S3 Gateway
The S3 gateway is a service that provides an S3-compatible interface to expose data in MapR Data Platform as objects. The S3 gateway manages all inbound S3 API requests to put data into and get data out of cloud storage.
The S3 gateway can expose data generated through multiple data protocols, such as NFS, POSIX, S3, and HDFS as objects.
The MapR Data Platform file system stores an object as a file. The file can be of any data type, but must have a unique name as part of the S3 API call. Files can be accessed by the S3 API requests and by MapR Data Platform file interfaces. Data objects are grouped into a logical container called a bucket. A bucket correlates with a folder in MapR Data Platform.
The following image shows the flow of data to and from MapR Data Platform:

You can use the S3 API to create, list, or
delete a bucket. You can also use it to get,
put, list, or delete a data object
within a bucket. The first time the S3 API accesses a file, it generates metadata. Metadata
is required to fulfill the API requests.
The S3 gateway also supports object notification through MapR Event Store For Apache Kafka. See Using the MapR Event Store For Apache Kafka for S3 Bucket Event Notifications.
S3 Deployment Mode
The S3 gateway only supports the Amazon S3 standalone deployment mode because each instance of the S3 gateway can only interact with one bucket or set of buckets at a time.
When you use the S3 API in standalone mode, each S3 gateway instance must have its own back-end directory in the MapR Data Platform file system. You can either map a volume mount point to the directory or use the directory path itself. An S3 instance exclusively uses the allocated directory or volume in the file system to serve an exclusive set of buckets.
The following deployment scenario shows one S3 gateway per cluster that supports multiple applications and multiple buckets with bucket sharing:
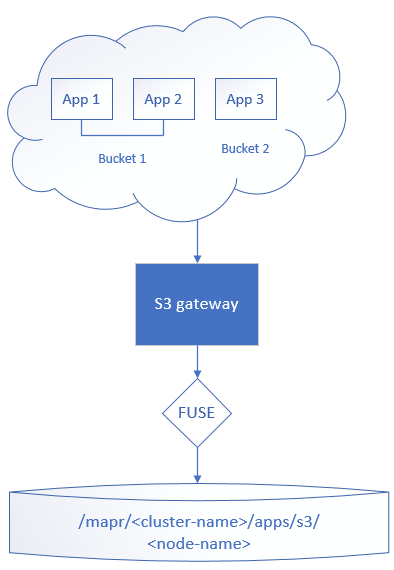
This scenario is useful if you want an application to access multiple buckets without knowing about bucket locations beforehand. The single S3 gateway instance serves all requests without having to partition any buckets.
If you need to migrate buckets to another S3 instance, you can move or copy the buckets to another directory or volume. See AWS CLI. If a bucket does not exist, an application can create a bucket through any S3 gateway; however, the bucket created will only be served through the one gateway.
Authorization to Access Data
By default, the S3 gateway provides a two-tier authorization model that starts with an S3 bucket policies check at the S3 REST API level, followed by a file permissions check on the MapR Data Platform.
When an S3 gateway instance receives a request from a tenant to access a bucket or object, it first checks for bucket policies that reference that particular tenant. If the tenant does not have access via the bucket policy, the request fails and no other checks are performed.
If the tenant has access via the bucket policy, the file system performs the next check using the mapped UID and GID credentials for the tenant.
Configuring S3 Gateway describes how to modify the type of authorization, configure tenants and credentials, and secure data. To see a configuration example, see Multi-Tiered Authorization Example.
Related Links
- For information about installation and configuration, see Installing S3 Gateway
- For a complete list of supported APIs, see Amazon S3 documentation
- For release-specific information, see S3 Gateway Release Notes
- For information about object tiering (archiving files in the cloud), see Data Tiering.