Spark
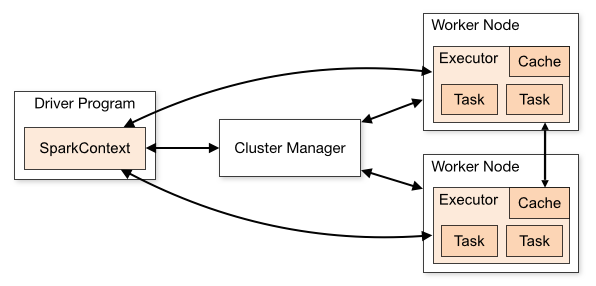
Apache Spark is an open-source processing engine that you can use to process Hadoop data. The following diagram shows the components involved in running Spark jobs. See Spark Cluster Mode Overview for further details on the different components.
MapR supports the following three types of cluster managers:
- Spark's own standalone cluster manager
- YARN
- Apache Mesos
NOTE: Spark on Mesos is available starting in the Spark 2.1.0-1707
release.
The configuration and operational steps for Spark differ based on the
Spark mode you choose to install. The steps to integrate Spark with other components are
the same when using Standalone and YARN cluster mode, except where otherwise noted. This section provides documentation about configuring and using Spark with MapR, but it does not duplicate the Apache Spark documentation.
You can also refer to additional documentation available on the Apache Spark Product Page.