MapR-DB and Apps
This section contains information about developing client applications for JSON and binary tables.
Why use MapR-DB?
From a developer's point-of-view, MapR-DB provides the following capabilities:
- Extreme scale for CRUD operations: Enabled by the integration of MapR-DB with the MapR File System, CRUD operations are extremely fast and efficient.
- Flexible data model: MapR-DB can be used as both a document database and a wide-column database. So if the content structure changes, the applications do not need to be re-written.
- Rich query: Integration with Drill for MapR-DB provides a low-latency distributed query engine for large-scale datasets, including structured and semi-structured/nested data.
- Integration with Apache Spark: MapR-DB provides MapR-DB Connectors for Apache Spark that allow you to access MapR-DB tables through Spark applications.
- Strong data consistency: Consistently fast response with strong data consistency with row/document level ACID transactions and in-memory database options for faster speeds.
MapR-DB JSON provides additional benefits:
- High performance via Secondary Indexes: No memory copying. No need to retrieve the full document to make updates due the log-based database architecture. No application changes needed to leverage secondary indexes for efficient query execution.
- Easy application development: JSON constructs such as maps, arrays, and data types are supported natively.
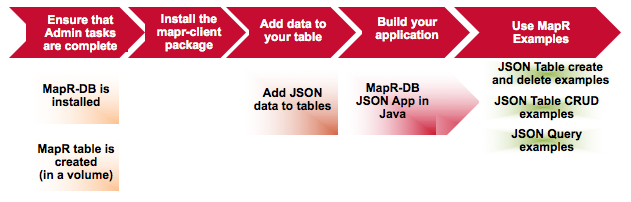
How Do I Get Started with MapR-DB JSON?
The following diagram illustrates an end-to-end flow associated with getting started with MapR-DB JSON.
You can also run through end-to-end examples using preconfigured, single node MapR clusters. The following table describes two options:
| MapR Sandbox | MapR Container for Developers |
|---|---|
|
The MapR Sandbox is a virtual machine (VM) that runs a single node MapR cluster. Sandbox Tutorial for JSON describes how to use that VM with MapR-DB JSON to do the following:
|
MapR Container for Developers is a Docker container that runs a single node MapR cluster. Using MapR-DB JSON: Getting Started, you can do the following:
|
Useful MapR-DB JSON Developer Resources
| Getting Started and Examples | Tools, Utilities, and Applications | General (Blogs, etc) | API Details |
|---|---|---|---|
| Managing JSON Tables - Examples creating, listing, and deleting MapR-DB JSON tables | maprcli and REST API Syntax | Data Modeling Guidelines for NoSQL JSON Document Databases |
MapR-DB JSON Client API NOTE: Beginning with MapR version 6.0,
the MapR-DB
Table interface in the MapR-DB JSON Client API is deprecated
and replaced by the DocumentStore interface in
the OJAI API library. See the next row for details on that
API. |
| Managing JSON Documents - Examples performing CRUD operations on JSON documents in MapR-DB JSON tables | Utilities for MapR-DB JSON Tables | App development with OJAI | Java OJAI Client API |
| Querying JSON Documents - Examples querying JSON documents in MapR-DB JSON tables | Drill on MapR | How to Build Applications on a NoSQL Document Database and Perform Analytics in Place | |
| Getting Started with the MapR-DB JSON REST API | Understanding the MapR-DB OJAI Connector for Spark | ||
| "MapR Music Catalog" Tutorial - Instructions and code to build a sample web application using MapR-DB JSON |
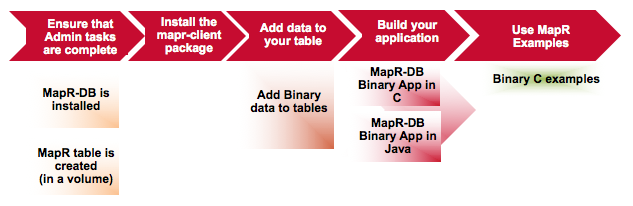
How Do I Get Started with MapR-DB Binary?
The following diagram illustrates an end-to-end flow associated with getting started with MapR-DB Binary.
Useful MapR-DB Binary Developer Resources
| Getting Started and Examples | Tools, Utilities, and Applications | General (Blogs, etc) |
|---|---|---|
| MapR-DB Sample C Application - C application example for binary tables | maprcli and REST API Syntax | High Performance C APIS on MapR-DB |
| Utilities for MapR-DB Binary Tables | ||
| Drill on MapR | ||
| MapR-DB Binary Connector for Apache Spark |