MapR Data Science Refinery
The MapR Data Science Refinery is an easy-to-deploy and scalable data science toolkit with native access to all platform assets and superior out-of-the-box security.
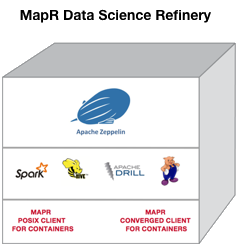
The MapR Data Science Refinery offers:
- Access to All Platform Assets
- The MapR FUSE-based POSIX Client allows app servers, web servers, and other client nodes and apps to read and write data directly and securely to a MapR cluster, like a Linux filesystem. In addition, connectors are provided for interacting with both MapR-DB and MapR-ES via Apache Spark connectors.
- Superior Security
- The MapR Platform provides enhanced security. Apache Zeppelin on MapR leverages and integrates with this security layer using the built-in capabilities provided by the MapR Persistent Application Container (PACC).
- Extensibility
- Apache Zeppelin is paired with the Helium framework to offer pluggable visualization capabilities.
- Simplified Deployment
- A preconfigured Zeppelin Docker container provides the ability to leverage MapR as a persistent data store.
Getting Started Using the Data Science Refinery with Zeppelin
There are multiple ways to deploy the Apache Zeppelin Docker container included in the Data Science Refinery as shown in the following diagram:
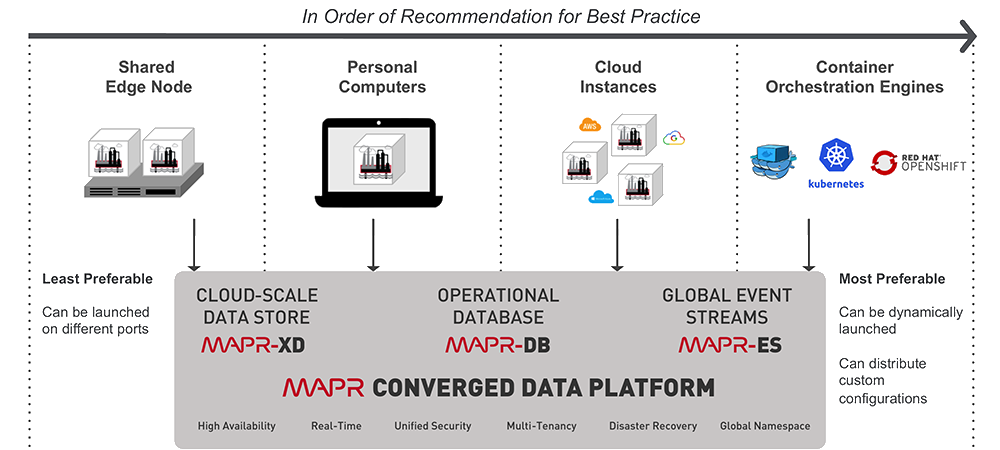
NOTE: Starting in version 1.2, you can deploy the Data Science Refinery on a MapR cluster
node. Make sure you take into consideration the resource requirements of the Data Science
Refinery, if you choose this deployment mode.
If you are already familiar with Apache Zeppelin on MapR and want to skip to the deployment instructions, see Running the Zeppelin Container.