Secondary Indexes
Beginning with data-fabric 6.0, HPE Ezmeral Data Fabric Database JSON natively supports secondary indexes on fields in JSON tables. Indexes provide you with flexible, high performance access to data stored in HPE Ezmeral Data Fabric Database.
How Do I Get Started?
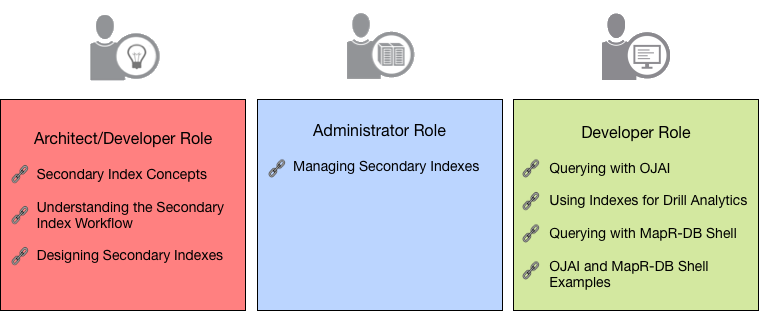
The following diagram provides links to topics that you need to understand and use
Secondary Indexes. Topics include conceptual information about indexes, how to decide what
indexes to create, how to set up and use indexes, the maprcli commands used
to create and maintain indexes, and how to query your data to leverage indexes. The
information is organized based on roles.
What are Secondary Indexes?
A secondary index (also sometimes referred to in this documentation as an index) is a special table that stores a subset of document fields from a JSON table. The index orders its data on a set of fields, defined as the indexed fields. This is in contrast to the JSON table that orders its data on the table primary key (rowId or rowKey). If you have administrator privileges, you can create one or more indexes on each JSON table. After the indexes are created, applications can leverage them to accelerate query response times. Secondary indexes can also contain additional fields known as included fields (or sometimes covered fields) beyond those being indexed, so that many queries can be satisfied with a single read.
Secondary indexes provide efficient access to a wider range of queries on data in HPE Ezmeral Data Fabric Database. They allow queries to efficiently query data through fields other than the primary key. This capability results in HPE Ezmeral Data Fabric Database supporting a broader set of use cases. Applications that benefit include rich, interactive business applications and user-facing analytic applications. Secondary indexes also enable Business Intelligence tools and ad-hoc queries on operational datasets. See Uses for Secondary Indexes for more information.
Why Use Secondary Indexes?
With the ever increasing amount of data stored in HPE Ezmeral Data Fabric Database JSON, indexing that data becomes critical. Without indexes, queries unnecessarily scan large amounts of data from the underlying JSON table. Queries could potentially scan every document in the table, even if they contain conditions that limit the documents to select. Query performance suffers and resource bottlenecks are inevitable when you use this data model.
Without indexes, applications and query layers resort to limited interactivity to avoid performance concerns. Using indexes solves this limitation in application scale, by reducing the number of documents client applications read, even when querying large data sets. This reduces I/O and CPU costs, resulting in improved performance.
The functionality and benefits of indexing available in HPE Ezmeral Data Fabric Database are similar to that of indexes in relational databases. The difference is that HPE Ezmeral Data Fabric Database indexes provide performance benefits at high scale, in combination with JSON flexibility on the query side and simplicity on the management side.
How Can I Use Secondary Indexes?
You can leverage HPE Ezmeral Data Fabric Database secondary indexes by using either the OJAI API, the HPE Ezmeral Data Fabric Database JSON REST API, or Drill.
OJAI is the business application development interface on HPE Ezmeral Data Fabric Database. Typically, business applications are characterized by ultra low latency and extremely high throughput. When you build an application using OJAI, filtering and sorting through the API can leverage secondary indexes to accelerate query response times.
The HPE Ezmeral Data Fabric Database JSON REST API enables you to use HTTP calls to perform basic operations on HPE Ezmeral Data Fabric Database JSON tables, including querying.
Drill is the analytics SQL interface on HPE Ezmeral Data Fabric Database. Drill is a distributed SQL query engine that provides interactive response time for operational analytics, Business Intelligence (BI) tools such as Tableau, and ad-hoc queries on HPE Ezmeral Data Fabric Database. With Drill, SQL queries can also leverage secondary indexes to accelerate query response times.
Regardless of whether queries originate from OJAI or Drill SQL, each interface seamlessly selects the optimal indexes to use. You do not need to write explicit code or provide directives on which indexes to use. If an appropriate index exists for a query, HPE Ezmeral Data Fabric Database leverages the index.
For more information about the OJAI API, see the following API links:
- Java OJAI Client API
- Node.js OJAI Client API
- Python OJAI Client API
- C# OJAI Client API
- Go OJAI Client API
For information about the HPE Ezmeral Data Fabric Database JSON REST API, see Using the HPE Ezmeral Data Fabric Database JSON REST API.
For information about MapR Drill, see Apache Drill on MapR.