Understanding the Secondary Index Workflow
Describes the overall workflow for using secondary indexes. This includes the roles of different users and the workflow steps involved.
Before deploying secondary indexes, it is assumed that you have installed and configured HPE Ezmeral Data Fabric Database and Drill to use secondary indexes, and have created and populated your HPE Ezmeral Data Fabric Database JSON tables. Implementing secondary indexes on JSON tables in HPE Ezmeral Data Fabric Database requires that you understand indexing concepts, know which administrative tasks to perform, and design your indexes to provide the most benefits for your queries.
The following diagram depicts the workflow and identifies the roles and order of tasks. Each step contains a link to a section in this page with further details.
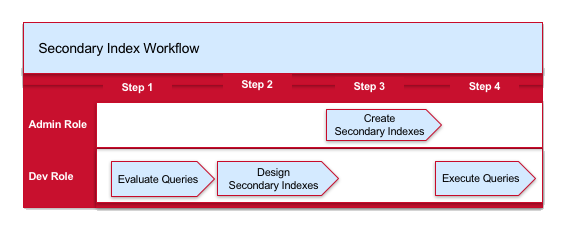
The following is a brief summary of each step:
- Evaluate your queries to identify those that can benefit from indexes.
- Design your indexes by determining which fields need to be indexed.
- Create your indexes using either the Control System or
maprcli. - Execute your queries.
How to Evaluate Queries that Benefit from Indexes
HPE Ezmeral Data Fabric Database JSON supports indexes with various properties. Each property benefits a certain class of queries. As part of deciding which of your queries will benefit from indexes, it is important to have a general understanding of these concepts. See Types of Secondary Indexes and Queries that Benefit from Secondary Indexes for more information.
How to Design Secondary Indexes
After you decide which queries can benefit from indexes, determine the set of indexes that provide the maximum benefits. See Designing Secondary Indexes for more information.How to Create Secondary Indexes
You can create secondary indexes using either the Control System or the maprcli table index command.
name field, use the
following maprcli
command:maprcli table index add -path /Data/business -index newIndex -indexedfields nameSee Managing Secondary Indexes for other commands to manage secondary indexes.
How to Query HPE Ezmeral Data Fabric Database JSON Tables
Depending on your use case, applications can access data in HPE Ezmeral Data Fabric Database through the following client interfaces:
- OJAI Client API
- Use for user-facing applications that need very high concurrency and ultra-low latency. The API is available in Java, Node.js, and Python.
- HPE Ezmeral Data Fabric Database JSON REST API
- Use for applications in which you want to access HPE Ezmeral Data Fabric Database JSON with HTTP calls.
- Drill SQL
- Use for performing operational analytics or Business Intelligence (BI) for medium-to-high complexity queries that require low-to-medium concurrency and interactive response times.
These APIs seamlessly select the optimal indexes to use. You do not need to write explicit code or provide directives on which indexes to use.
The following diagram summarizes the components involved in the different scenarios.
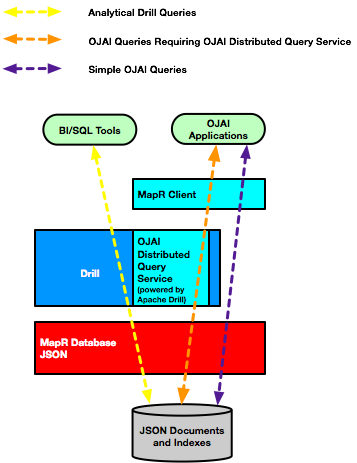
For OJAI applications, the HPE Ezmeral Data Fabric client chooses the more appropriate of two possible execution paths, without user interaction. One of the paths leverages the OJAI Distributed Query Service, which supports more advanced index selection and parallel query execution. It also supports sorting large data sets. For example, if the sort order specified in your OJAI query does not match the sort order of an index, the HPE Ezmeral Data Fabric client automatically invokes the OJAI Distributed Query Service to perform the sort.