Getting Started with CDC
Describes an end-to-end flow of how to establish and use Change Data Capture (CDC). It assumes that a new table and dataset will be created, although an existing table with data can also be used.
End-to-End Workflow
The following diagram shows an end-to-end workflow of the Change Data Capture (CDC)
feature.
NOTE Steps 2 and 3 are interchangable. You may decide to start the consumer
application for CDC changed data records before performing CRUD operations on the
table.
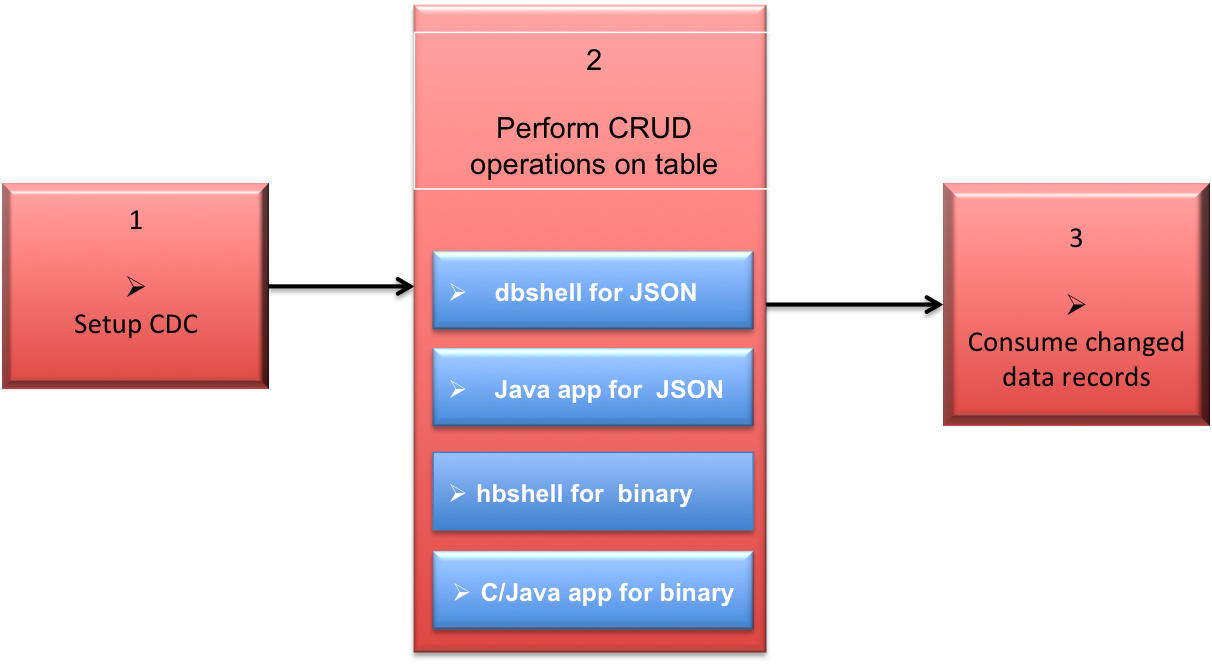
- Setup the CDC environment.
- If you are propagating changed data from a source table on a source cluster to a destination stream topic on a remote destination cluster, you must setup a gateway. Gateways are setup by installing the gateway on the destination cluster and specifying the gateway node(s) on the source cluster. See Administering Data Fabric Gateways and Configuring Gateways for Table and Stream Replication.
- If you have a secure cluster, you must set up secure configuration. See Configuring Secure Clusters for Cross-Cluster Mirroring and Replication.
- Establish a HPE Ezmeral Data Fabric Database table (JSON or binary) with data. You can create a new table and add data, or use an existing table with data. See maprcli table create for creating a new table or use the Control System. If you are using an existing table with data, skip to the next step.
- Create a HPE Ezmeral Data Fabric Streams stream for the propagated
changed data records using the
maprcli stream create -ischangelogparameter. See maprcli stream create or use the Control System. - Create a HPE Ezmeral Data Fabric Streams stream topic for the changed data records. You can use the maprcli stream topic create command, the maprcli table changelog add command (this command creates a changelog relationsip between the source table and the destination stream topic), or the Control System when creating either a stream topic or a table changelog.
- Create a changelog relationship between the source table and the destination stream
topic with the maprcli
table changelog add command or use the Control System. By creating a
changelog relationship, you are creating an environment that propagates changed data
records from a source table to a HPE Ezmeral Data Fabric Streams topic.
NOTE Propagation of existing table data is enabled by default. If you do not want to propagate existing source table data, set the
-propagateexistingdataparameter to false. The default istrue.NOTE Propagation is enabled as soon as you add the table changelog relationship. If you do not want propagation to begin, set the-pauseparameter to true. The change data records are stored in a bucket until you resume the changelog relationship; at this point, the stored change data records are propagated to the stream topic. See table changelog resume for more information. - Verify that the changelog exists. See table changelog list for information about your changelogs.
- Perform CRUD operations (inserts, updates, and deletes) on the source table. The following utility and application can be used:
- Write a consumer with the Apache Kafka and OJAI API libraries that subscribes to the topic and consumes the change data records. There are multiple interfaces that are used for writing a CDC consumer. See Consuming CDC Records for a list of interfaces. See Building Consumers for CDC for an example.
Use Cases
| Scenario | Setup Task | Notes |
|---|---|---|
| You want a CDC stream topic to contain all of the table data as changed data records. | You would setup CDC in the following manner before performing operations on
the source table and consuming the change data records.
|
In this case, all table data is propagated to the stream topic as change data records and the operation type is identified on each individual data record. |
| You want a CDC stream topic to contain all of the existing table data and changed data records. | You would setup CDC in the following manner before performing operations on
the source table and consuming the change data records.
|
In this case, the existing table data is propagated to the stream topic and
that data's operation type is identified as a SET operation. Subsequently,
operations on the source table are propagated as changed data records and the
operation type is identified on each individual data record. You can consume
data at any time, however, there may be a delay before all of the existing table
data is completely propagated, expecially if you have a large dataset. Be sure
to check the |
| You want a CDC stream topic to not contain any original table data and to capture only subsequent changed data records | You would setup CDC in the following manner before performing operations on
the source table and consuming the change data records.
|
In this case, the existing table data is not propagated to the stream topic and the operation type is identified on each individual data record. |