Connecting Drill to Data Sources
Choose and configure storage plugins to enable Drill to connect to a data source.
Drill serves as a query layer that connects to data sources through storage plugins. A storage plugin is a software module for connecting Drill to data sources. A storage plugin typically optimizes execution of Drill queries, provides the location of the data, and configures the workspace and file formats for reading data.
What you can do with Storage Plugins
Several storage plugins are installed with Drill that you can configure to suit your environment. Through a storage plugin, Drill connects to a data source, such as a database, a file on a local or distributed filesystem, or a Hive metastore. See the Drill Storage and Format Plugin Support Matrix.
You can modify the default configuration of a storage plugin and give the new configuration a unique name. This document refers to Y as a different storage plugin, although it is actually just a reconfiguration of original interface.
On the Storage tab of the Web Console, you can view and reconfigure a storage plugin if you have permission. You can access each node running a Drillbit by starting the Drill Web Console. The way you start the Drill Web Console depends on your security setup.
When you install Drill using the mapr-drill package, storage plugin
configurations are available for the following data sources:
- file system
- HPE Ezmeral Data Fabric DatabaseNOTE To access HPE Ezmeral Data Fabric Database tables, use the dfs storage plugin with the maprdb format plugin.
- Hive
- Kafka
Connecting Drill to HBase
As of the Core 6.0 and Drill 1.11, HBase is no longer supported, therefore the communication path between Drill and HBase is also not supported. If you have an hbase storage plugin configured in Drill, you should disable it.
Default Storage Plugin Configurations
The Drill documentation describes the attributes and definitions that you can configure for storage plugins, except for the HPE Ezmeral Data Fabric Database format. See HPE Ezmeral Data Fabric Database Format Plugin for Drill.
| Instance | Description |
|---|---|
| cp | Points to a JAR file in the Drill classpath that contains the Transaction Processing Performance Council (TPC) benchmark schema TPC-H that you can query. |
| dfs | Points to file system by default. Drill automatically configures this instance when you install Drill in a the cluster. Includes a maprdb format plugin for HPE Ezmeral Data Fabric Database. |
| hive | Integrates Drill with the Hive metadata abstraction of files, HPE Ezmeral Data Fabric Database, and libraries to read data and operate on SerDes and UDFs. |
When you add or update a storage plugin configuration on one Drill node in a Drill cluster, Drill broadcasts the information to all of the other Drill nodes. All nodes have identical storage plugin configurations. You do not need to restart any Drillbits when you add or update a storage plugin configuration.h
Configuring Storage Plugin Instances
You can add, remove, or update Drill storage plugin configurations using the Web Console. The following image shows the default storage plugin configurations in the Drill Web UI:
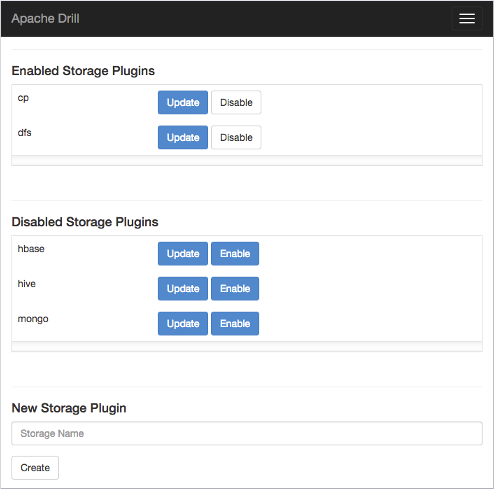
If you click Update next to dfs, the following default
configuration appears :
{
"type": "file",
"enabled": true,
"connection": "maprfs:///",
"workspaces": {
"root": {
"location": "/",
"writable": false,
"defaultInputFormat": null
},
"tmp": {
"location": "/tmp",
"writable": true,
"defaultInputFormat": null
}
},
"formats": {
"psv": {
"type": "text",
"extensions": [
"tbl"
],
"delimiter": "|"
},
"csv": {
"type": "text",
"extensions": [
"csv"
],
"delimiter": ","
},
"tsv": {
"type": "text",
"extensions": [
"tsv"
],
"delimiter": "\t"
},
"parquet": {
"type": "parquet"
},
"json": {
"type": "json"
},
"maprdb": {
"type": "maprdb"
}
}
}The dfs configuration includes the storage plugin type, connection
information, default workspaces, and file formats that the data source supports. You can add
and remove workspaces and file formats.
Changing the Connection Attribute
You can also change the connection if you want the configuration to point to a different cluster.
By default, Drill connects to the cluster that the Drill node belongs to. You do not need to modify the connection unless you want to connect Drill to a different cluster. To connect to a different cluster, edit the connection to include the name of the cluster that you want to connect to.
"connection": "maprfs://<cluster_name>/"