Asynchronous Secondary Index Updates
Secondary indexes are updated asynchronously. The asynchronous approach favors performance and scalability over synchronous, transactional updates. However, this also means that indexed data can be stale compared to data in the JSON table, even though the data eventually becomes consistent with the JSON table data.
Impact of Asynchronous Indexes
By updating the index asynchronously, this avoids delaying updates to the JSON table.
From a user point of view, secondary indexes updates are complete when the HPE Ezmeral Data Fabric Database table data appears in the index. This occurs without application developers having to write any explicit code. Because indexes are asynchronously updated relative to the JSON table, there is a lag in updates appearing in the index. For a reasonably sized cluster, secondary index updates will typically occur within a few seconds of the update on the JSON table. When the JSON table and its secondary indexes are on separate nodes, the updates to the index are more expensive. The lag is potentially higher.
The following example illustrates how the lag in updates impacts queries that use indexes.
Suppose you have a JSON table that has a document with _id=DOC1. An update
occurs on the indexed field, a.b.c, changing the value from v1 to v2. For
queries that use a covering
index, any of the following values might be returned for the (_id,
a.b.c) pair:
- Only (DOC1,v1) - This occurs if the new value v2 has not yet been indexed.
- Only (DOC1,v2) - This occurs if the new value v2 is indexed and the old value v1 is deleted.
- Both (DOC1,v1) and (DOC1,v2) - This occurs if the new value v2 is indexed and the old value v1 is not yet deleted.
- Neither (DOC1,v1) nor (DOC1,v2) - This occurs if the value v1 is not indexed. The newer value v2 is not yet indexed, because value v1 is always indexed first.
For queries that use non-covering indexes, HPE Ezmeral Data Fabric Database re-reads the indexed and included fields when reading additional fields from the JSON table. This ensures that the query results are consistent in spite of update lags.
In the case where a non-covering index provides the ordering for the ORDER BY specification of a query, index lag can result in a partial sort of the result. See Partial Sorts with Non-Covering Indexes for further details.
See Troubleshooting Secondary Indexes for information about how to determine if an index is lagging its JSON table.
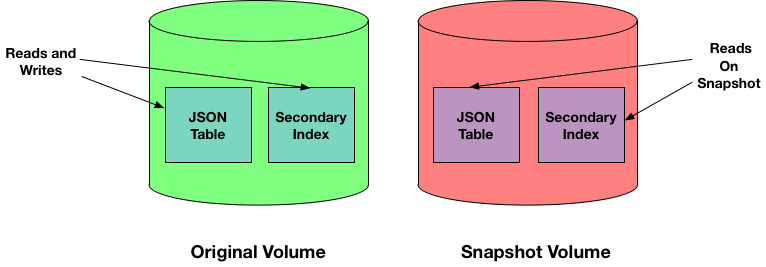
Snapshots
Queries against snapshots containing tables with secondary indexes can return inconsistent results. This occurs if the data queried is actively changing at the time of snapshot creation. When creating a snapshot, if a secondary index on a JSON table does not have current data due to asynchronous updates of the index, the snapshot retains the lag in updates. The lag leads to the following behavior, which is similar to the behavior discussed in the previous section.
- For a query using a covering index, if the indexed data is out of sync, the query could return data that is current, old, or both.
- For a query using a non-covering index, if the indexed data is out of sync, the query returns the most recent data records.
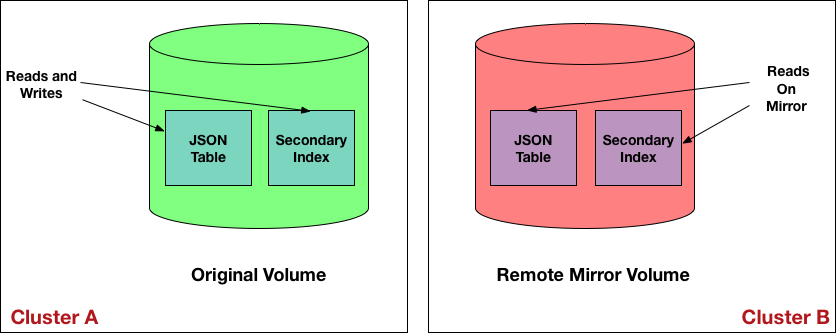
Mirroring
Queries against mirror volumes behave like queries against snapshots. Lags in the source volume carry over into the mirror volume. Upon refreshing a mirror volume, the lag can resolve itself.
Reading Your Own Write Operations
Certain classes of applications require users to immediately see the data they have written. In these cases, getting stale data can confuse users. Think about an expense report application example where the user enters his expenses and wants to immediately see the entries. The asynchronous nature of indexes could be an issue in such a case. To avoid the possibility of reading stale data due to asynchronous indexes, the Java OJAI API Library provides functionality that enables you to read the result of your own write operation. See Reading Your Own Writes in Java OJAI to learn about how to use this feature in your application.