Impala
Overview
Impala is an open source, interactive SQL engine for Hadoop that you can use to access data on clusters. With Impala, you can use business intelligence (BI) tools to run ad-hoc queries directly on Hadoop. Impala provides the following benefits:
- Broad availability of Hadoop data to the business community
- Leverages familiar SQL tools and skill sets on Hadoop
- Full fidelity data analysis
- Cost savings by offloading from traditional DWH/Analytics platforms
- Time savings because you do not have to move around data
Impala uses the Apache Hive query language (HiveQL) and Hive metadata. You can use the most common SQL-92 features of HiveQL, including SELECT, joins, and aggregate functions to query data in your cluster. You can issue queries from the impala-shell command-line tool, or through an ODBC or JDBC client. When you submit a query, Impala works with other components in the cluster to process the query.
Impala uses the Hive metastore to store metadata. The Hive metastore is typically the same database that Hive uses to store metadata. Impala can access tables you create in Hive when they contain datatypes, file formats, and compression codecs that Impala supports.
If you have HPE Ezmeral Data Fabric Database configured to store table data, you can define the tables in Hive and then map them to equivalent tables in HPE Ezmeral Data Fabric Database. After you map the tables, you can use Impala to query the HPE Ezmeral Data Fabric Database tables and perform table joins between HPE Ezmeral Data Fabric Database and Hive tables.
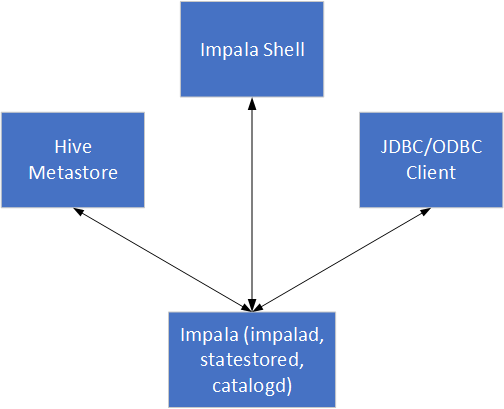
The following table contains a list of components that work together to process a query issued to Impala:
|
Component |
Description |
|
Clients |
The impala-shell, JDBC client, or ODBC client that you connect to Impala from. You issue a query to Impala from the client. |
|
Hive Metastore |
Stores information about the tables that Impala can access. |
|
Impala (impalad, statestored, catalogd) |
Impalad is a process that runs on designated nodes in the cluster. It coordinates and runs queries. Each node running the Impala process can receive, plan, and coordinate queries sent from a client. Statestored tracks the state of the Impalad processes in the cluster. Catalogd communicates new or updated metadata to all the other Impala nodes when Impala changes table data or metadata on a node. |
|
file system/HPE Ezmeral Data Fabric Database |
file system is the filesystem that stores data files and tables. HPE Ezmeral Data Fabric Database stores tables natively. |
Impala Daemon
The Impala daemon (impalad) is the core Impala process. Install the impala server package on all nodes that you want to run the Impala service on. You can submit queries to any node configured with the Impala daemon. When you submit a query to a node running the Impala daemon process, the node becomes the central coordinator for the query. The coordinator distributes work to the other nodes running the Impala daemon process to complete the query request.
The coordinator node running the Impala daemon process completes the following tasks:
- Accepts the query from the client
- Parallelizes queries and distributes pieces of the query to other impalad nodes
- Receives query results from other impalad nodes
- Builds the final result set for the query and passes it to the client
- Communicates with the statestore service
All nodes running the Impala daemon process perform the following tasks:
- Read and write data to files
- Transmit partial query results back to the coordinator
- Communicate with the statestore service
Impala Statestore
The Impala statestore service (statestored) verifies the health of nodes running the Impala daemon process. The node running the statestore service communicates node health to all nodes running the Impala daemon process. The statestore service ensures that impalad nodes only pass query work to active nodes running the Impala daemon process.
If the node running the statestore service goes offline, other Impala nodes continue the query work. If any of the other Impala nodes go offline while the statestore service is unavailable, query time may increase. The statestore service can automatically communicate with the Impala nodes and resume work when the node is back online.
Catalog Service
The catalog service (catalogd) resides on the same node as statestored. The catalog
service communicates new or updated metadata to all of the other Impala nodes when
Impala changes table data or metadata on one node. You no longer need to use the
REFRESH or INVALIDATE METADATA statements after
issuing the following statements to Impala:
-
CREATE TABLE -
ALTER TABLE -
DROP TABLE -
INSERT -
LOAD DATA
The catalog service only works on operations performed through Impala. If you perform
operations through the Hive shell or through file system, you
must issue the REFRESH and INVALIDATE METADATA
statements. The catalog service broadcasts the results of the REFRESH
and INVALIDATE METADATA operations to other Impala nodes so that you
only have to issue the statements once.
The following image represents how the various components communicate:
Query Execution
Each node running the Impala service can receive, plan, and coordinate queries. The Impala daemon process on each node listens for requests from ports on each client. Requests from the impala-shell are routed to the impala daemons through one particular port. JDBC and ODBC requests are routed through other ports.
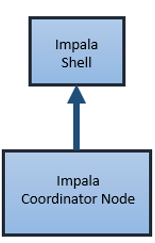
When you send a query to Impala, the client connects to a node running the Impala process. The node that the client connects to becomes the coordinator for the query.
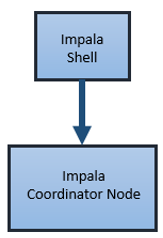
The coordinator node parses the query into fragments and analyzes the query to determine what tasks the nodes running Impala must perform. The coordinator distributes the fragments across other nodes running the Impala daemon process. The nodes process the query fragments and return the data to the coordinator node.

The coordinator node sends the result set back to the client.