Drill Limitations
Provides information about Drill limitations and solutions where applicable.
Working with subqueries
- The SELECT list in a scalar subquery can only contain one item/column.
- Correlated subqueries should return exactly one row.
- The WHERE clause of a subquery should not refer to more than one column of the table in the outer query.
Queries on JSON Files and Tables in HPE Ezmeral Data Fabric Return an OutOfMemoryException
An architectural limitation in Apache Drill can cause an overconsumption of memory when Drill queries files or tables with a certain JSON structure, resulting in an OutOfMemoryException.
Drill may return an OutOfMemoryException for queries that run against JSON files stored in HPE Ezmeral Data Fabric Database and HPE Ezmeral Data Fabric File Store that have many key-value pairs if the queries include the key-value pairs.
- JSON file with objects that have many key-value pairs
-
{ "context" : { "1": "a", "2": "b", "3": "c", ... // many key-value pairs; not showing 9996 of them "10000": "d" } } { "context" : { "10001": "b" ... //many key-value pairs; not showing 19998 of them "30000": "z" } } { "context" : { "3": "c" } } { "context" : { } } { "context" : { "5": "e" } } - JSON file with thousands of objects, each having a unique key
-
{ "context" : { "1": "a" } } { "context" : { "2": "b" } } { "context" : { "3": "c" } } { "context" : { "4": "d" } } { "context" : { "5": "e" } }
Issue Cause
Drill was designed to run queries against massive amounts of data. To successfully run such queries, Drill has a columnar execution engine that works with vectors. Drill creates a separate vector for each unique key and then allocates memory to each vector. Each vector stores about 1,024 values, which varies slightly depending on the data type of the value.
In the following illustration, each key has a VARCHAR value and Drill creates a NullableVarCharVector for each unique key:
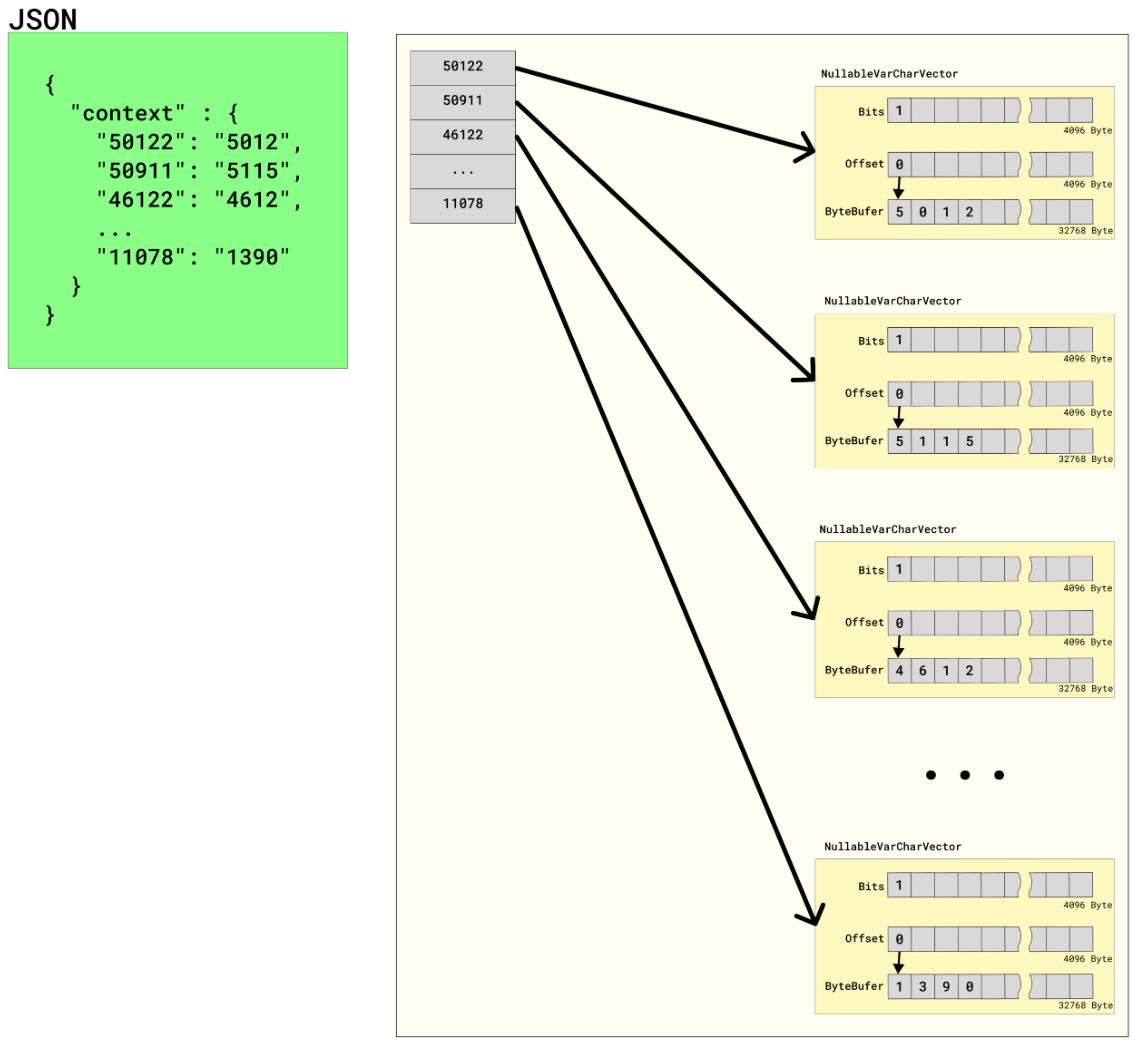
Drill allocates 40960 bytes of direct memory to each NullableVarCharVector. You can see how Drill fills each vector with 7 bytes (2 bytes for a single CHAR string, like "a" and 5 bytes for internally used values).
In cases where Drill is querying thousands upon thousands of JSON files, this works well. However, in cases where Drill queries a single file, a memory issue occurs because each key-value pair in the JSON file may consume more than 1000x more memory than is required for the corresponding value. Each vector unnecessarily holds memory for several values, resulting in failed queries due to a memory shortage.
Refer to Value Vectors for more information about vectors in Drill.
Issue Resolution
{
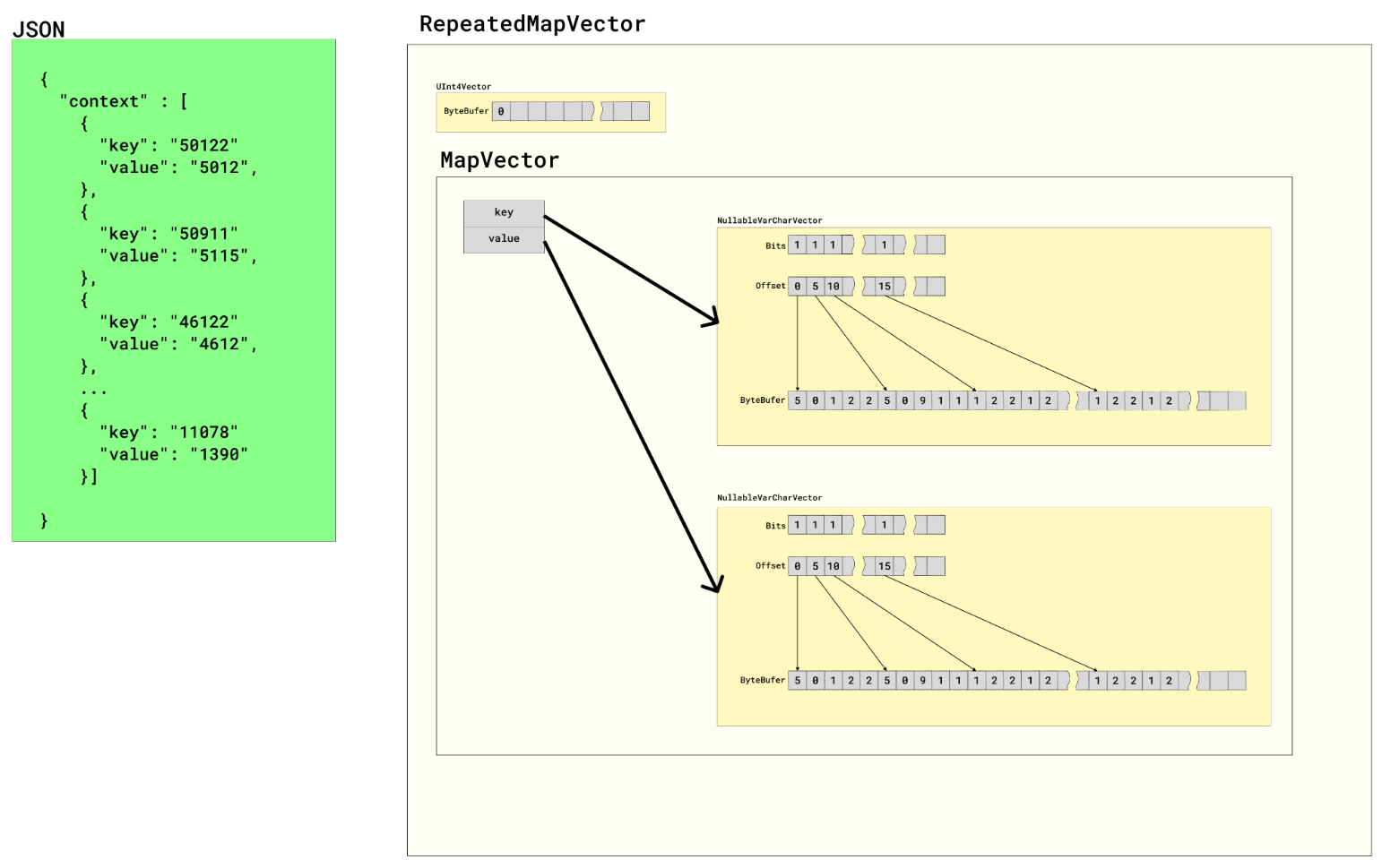
"context" : [
{
"key": "1",
"value": "a"
},
{
"key": "2",
"value": "b"
},
{
"key": "3",
"value": "c"
},
...,
{
"key": "100000",
"value": "z"
}
]
}
When a JSON file has an array of objects, Drill only creates two NullableVarCharVectors – one for the "key" and one for the "value". With this structure, only two vectors need to hold memory.
In the following illustration, you can see how Drill fills two vectors with many values versus filling thousands of vectors with only a few values: