Troubleshooting Zeppelin
This section describes how to resolve common problems you may encounter when using Apache Zeppelin.
Problems Starting Zeppelin
- Problem
Your
docker runcommand fails with the following message:Zeppelin start [FAILED]- Possible Cause
You have configured Docker with too little memory
- Resolution
-
Reconfigure Docker with at least 3.5 GB of memory
Problems Connecting to Zeppelin UI
- Problem
-
You specify storing your notebooks in a MapR File System and encounter the following error when trying to connect to Zeppelin in your browser:
HTTP ERROR: 503
| Possible Cause | Resolution |
|---|---|
ZEPPELIN_NOTEBOOK_DIR is set to an incorrect MapR File System directory in your docker run
command |
Verify that you have set ZEPPELIN_NOTEBOOK_DIR to a valid
MapR File System directory |
| Problems with the FUSE-Based POSIX Client | Apply the MapR Data Platform POSIX Client for Containers license if you are missing this license |
| Problems with your MapR ticket file | Make sure you have correctly set up your MapR ticket file, including setting the proper owner and group on your source ticket file. See MapR Ticketing for details. |
See Notebook Storage for further details.
Problems Logging into the Zeppelin UI
- Problem
-
Log in fails even though you have specified a correct username and password
- Possible Cause
-
You have configured Docker with too little memory
- Resolution
-
Reconfigure Docker with at least 3.5 GB of memory
Navigation Problems in Zeppelin UI
- Problem
Zeppelin UI screens do not display correctly in your browser
- Possible Cause
Due to security requirements, connecting to Zeppelin requires self-signed certificates
- Resolution
Make sure you accept any certificates when connecting to Zeppelin. The following shows the prompts you need to click in the Safari browser:
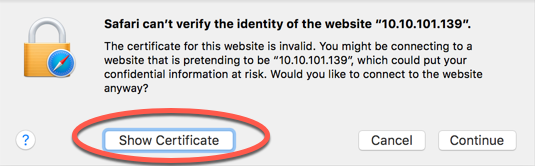
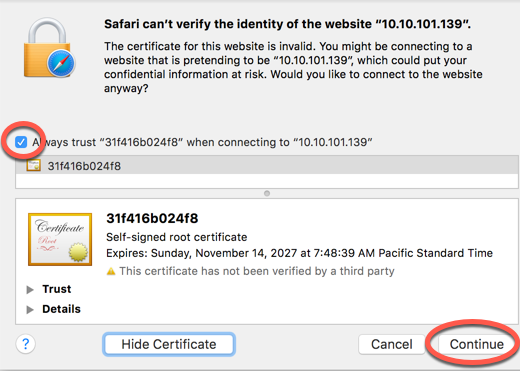
Unable to Access the MapR File System
- Problem
-
You are using the MapR FUSE-Based POSIX Client to access the MapR File System, and your MapR filesystem mount point is empty.
- Possible Cause
-
Missing MapR POSIX Client for Containers license
- Resolution
-
Install the necessary license. See FUSE-Based POSIX Client for further details.
FileClient Errors
- Problem
Running
lseither in the Zeppelin shell interpreter or inside your container returns the following error:ls: Could not create FileClient- Possible Cause
Invalid MapR ticket
- Resolution
Make sure you have a valid ticket with the proper permissions. You must generate a unique ticket for each MapR cluster. See MapR Ticketing for further details.
Livy Errors when Using Bridge Networking
- Problem
-
You are using bridge networking, and all commands you run in the Livy interpreter return errors. You see an error similar to the following in the Zeppelin UI:
org.apache.zeppelin.livy.LivyException: Session 0 is finished, appId: application_1511983726844_0005, log: [ at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624), at java.lang.Thread.run(Thread.java:748), , Shell output: main : command provided 1, main : user is mapr, main : requested yarn user is mapr, , , Container exited with a non-zero exit code 15, Failing this attempt. Failing the application.] - Possible Cause
-
You have not correctly specified the
HOST_IPor Livy launcher's port range as described at bridge networking. - Solution
-
Make sure your
docker runcommand includes the noted parameters. In particular, make sure you do not specifylocalhostas theHOST_IPif you are running the container and Zeppelin UI on the same machine. If you are running multiple Zeppelin containers on a single host, make sure you specify unique port ranges for the Livy launcher as described at Running Multiple Zeppelin Containers on a Single Host.
Livy and Pig Errors when Using Bridge Networking
- Problem
You are using bridge networking and encounter errors when using the Livy and Pig interpreters.
- Possible Cause
-
The errors may be due to DNS issues. Bridge networking, which is the Docker default, may override your DNS settings. Examine your Zeppelin Log Files to see if there are errors related to unknown hosts.
Sample of errors in the case of Livy are the following:
- Livy interpreter output in the Zeppelin
UI:
org.apache.zeppelin.livy.LivyException: Session 0 is finished, appId: null, log: [java.lang.RuntimeException: Unable to create proxy to the ResourceManager null, org.apache.hadoop.yarn.client.MapRZKBasedRMFailoverProxyProvider.getProxy(MapRZKBasedRMFailoverProxyProvider.java:135) ... - Exceptions in the Livy log file (
/opt/mapr/livy/livy-0.5.0/logs/livy-mapruser1-server.out):17/11/08 14:41:02 INFO ContextLauncher: 17/11/08 14:41:02 FATAL zookeeper.ZKDataRetrieval: Could not create ZooKeeper instance. Due to IOException. No data from ZK with connect string: node1:5181 will be returned. 17/11/08 14:41:02 INFO ContextLauncher: java.net.UnknownHostException: node1: Name or service not known 17/11/08 14:41:02 INFO ContextLauncher: at java.net.Inet4AddressImpl.lookupAllHostAddr(Native Method) ... 17/11/08 14:41:02 INFO ContextLauncher: 17/11/08 14:41:02 ERROR client.MapRZKBasedRMFailoverProxyProvider: Unable to create proxy to the ResourceManager null 17/11/08 14:41:02 INFO ContextLauncher: 17/11/08 14:41:02 INFO service.AbstractService: Service org.apache.hadoop.yarn.client.api.impl.YarnClientImpl failed in state STARTED; cause: java.lang.RuntimeException: Unable to create proxy to the ResourceManager null 17/11/08 14:41:02 INFO ContextLauncher: java.lang.RuntimeException: Unable to create proxy to the ResourceManager null 17/11/08 14:41:02 INFO ContextLauncher: at org.apache.hadoop.yarn.client.MapRZKBasedRMFailoverProxyProvider.getProxy(MapRZKBasedRMFailoverProxyProvider.java:135) ...
Samples of errors in the case of Pig are the following:
- Pig interpreter output in the Zeppelin
UI:
org.apache.pig.impl.logicalLayer.FrontendException: ERROR 1066: Unable to open iterator for alias paragraph_20161228_140730_1903342877 at org.apache.pig.PigServer.openIterator(PigServer.java:1032) ... - Exceptions in the Pig log file (
/opt/mapr/zeppelin/zeppelin-0.8.0/logs/zeppelin-interpreter-pig-mapruser1-a384f3320c46.log):INFO [2017-11-08 14:30:13,346] ({pool-2-thread-3} ZooKeeper.java[<init>]:438) - Initiating client connection, connectString=node1:5181 sessionTimeout=30000 watcher=com.mapr.util.zookeeper.ZKDataRetrieval@5de4a6da FATAL [2017-11-08 14:30:13,544] ({pool-2-thread-3} ZKDataRetrieval.java[init]:105) - Could not create ZooKeeper instance. Due to IOException. No data from ZK with connect string: node1:5181 will be returned. java.net.UnknownHostException: node1: Name or service not known at java.net.Inet4AddressImpl.lookupAllHostAddr(Native Method)
- Livy interpreter output in the Zeppelin
UI:
- Resolution
- Add the following parameter to
docker run:--dns=<nameserver-that-resolves-cluster-hosts>
Problems Running PySpark or SparkR Code
- Problem
You are unable to run PySpark or SparkR code in either the Livy or Spark interpreter.
- Possible Cause
-
You have different versions of the Python or R libraries in your Zeppelin container and your MapR cluster.
- Resolution
Install matching versions of the libraries in your MapR cluster.
Or, choose the Zeppelin Docker image OS that matches the OS running in your MapR cluster. This minimizes version differences between the libraries running in your container and your MapR cluster.
NPE Using the Spark Interpreter
- Problem
-
You encounter an NPE when you use the Spark interpreter.
- Possible Cause
-
The directory
/apps/sparkis missing in your MapR cluster. If this is the case, you will see the following error in your Zeppelin Spark interpreter log file:ERROR [2018-03-23 16:40:22,120] ({pool-2-thread-2} Utils.java[invokeMethod]:40) - java.lang.reflect.InvocationTargetException ... Caused by: java.io.FileNotFoundException: Requested file maprfs:///apps/spark does not exist. at com.mapr.fs.MapRFileSystem.getMapRFileStatus(MapRFileSystem.java:1438) at com.mapr.fs.MapRFileSystem.getFileStatus(MapRFileSystem.java:1086) at org.apache.spark.scheduler.EventLoggingListener.start(EventLoggingListener.scala:94) at org.apache.spark.SparkContext.<init>(SparkContext.scala:531) at org.apache.spark.SparkContext$.getOrCreate(SparkContext.scala:2516) at org.apache.spark.sql.SparkSession$Builder$$anonfun$6.apply(SparkSession.scala:918) at org.apache.spark.sql.SparkSession$Builder$$anonfun$6.apply(SparkSession.scala:910) at scala.Option.getOrElse(Option.scala:121) at org.apache.spark.sql.SparkSession$Builder.getOrCreate(SparkSession.scala:910) ... 20 more INFO [2018-03-23 16:40:22,121] ({pool-2-thread-2} SparkInterpreter.java[createSparkSession]:362) - Created Spark session with Hive support ERROR [2018-03-23 16:40:22,121] ({pool-2-thread-2} Job.java[run]:181) - Job failed java.lang.NullPointerException - Resolution
-
Create the directory
/apps/sparkon your MapR cluster as described at Installing Spark on YARN. - Possible Cause
-
The credentials on your MapR ticket are incorrect. If this is the case, you will see the following errors in your Zeppelin Spark interpreter log file:
ERROR [2018-03-26 22:47:48,967] ({pool-2-thread-2} Utils.java[invokeMethod]:40) - java.lang.reflect.InvocationTargetException ... Caused by: java.io.IOException: failure to login: javax.security.auth.login.LoginException: Unable to obtain MapR credentials at org.apache.hadoop.security.UserGroupInformation.loginUserFromSubject(UserGroupInformation.java:751) at org.apache.hadoop.security.UserGroupInformation.getLoginUser(UserGroupInformation.java:688) at org.apache.hadoop.security.UserGroupInformation.getCurrentUser(UserGroupInformation.java:572) at org.apache.spark.util.Utils$$anonfun$getCurrentUserName$1.apply(Utils.scala:2424) at org.apache.spark.util.Utils$$anonfun$getCurrentUserName$1.apply(Utils.scala:2424) at scala.Option.getOrElse(Option.scala:121) at org.apache.spark.util.Utils$.getCurrentUserName(Utils.scala:2424) at org.apache.spark.SparkContext.<init>(SparkContext.scala:295) at org.apache.spark.SparkContext$.getOrCreate(SparkContext.scala:2516) at org.apache.spark.sql.SparkSession$Builder$$anonfun$6.apply(SparkSession.scala:918) at org.apache.spark.sql.SparkSession$Builder$$anonfun$6.apply(SparkSession.scala:910) at scala.Option.getOrElse(Option.scala:121) at org.apache.spark.sql.SparkSession$Builder.getOrCreate(SparkSession.scala:910) ... 20 more Caused by: javax.security.auth.login.LoginException: Unable to obtain MapR credentials at com.mapr.security.maprsasl.MaprSecurityLoginModule.login(MaprSecurityLoginModule.java:228) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at javax.security.auth.login.LoginContext.invoke(LoginContext.java:755) at javax.security.auth.login.LoginContext.access$000(LoginContext.java:195) at javax.security.auth.login.LoginContext$4.run(LoginContext.java:682) at javax.security.auth.login.LoginContext$4.run(LoginContext.java:680) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.login.LoginContext.invokePriv(LoginContext.java:680) at javax.security.auth.login.LoginContext.login(LoginContext.java:587) at org.apache.hadoop.security.UserGroupInformation.loginUserFromSubject(UserGroupInformation.java:724) ... 32 more Caused by: com.mapr.login.MapRLoginException: Unable to load ticket file '/tmp/mapr_ticket', error = 13 at com.mapr.login.client.MapRLoginHttpsClient.authenticateIfNeeded(MapRLoginHttpsClient.java:149) at com.mapr.login.client.MapRLoginHttpsClient.authenticateIfNeeded(MapRLoginHttpsClient.java:115) at com.mapr.security.maprsasl.MaprSecurityLoginModule.login(MaprSecurityLoginModule.java:222) ... 44 more - Resolution
-
Make sure you have correctly set up your MapR ticket file, including setting the proper owner and group on your source ticket file. See MapR Ticketing for details.
Hangs when Using the Spark Interpreter
- Problem
-
You encounter hangs when running code using the Spark interpreter.
- Possible Cause
-
You are using bridge networking and have not reserved the ports used by the Spark driver.
- Resolution
-
Add the following to your
docker runcommand:-p 11000-11010:11000-11010See Bridge Networking for further details.
MapR Credential Errors
- Problem
- Your MapR cluster is secure and you encounter the following error while trying to access the cluster:
Unable to obtain MapR credentials - Possible Cause
This is likely a problem with your MapR ticket.
- Resolution
As described in the MapR Ticketing section that discusses
docker runparameters, make sure the following are true:- All identity parameters (user name, group name, UID, and GID) are consistent with the values specified in the ticket file.
- The owner and group on the source ticket file match the UID and GID specified in the ticket file.
chowncommand:sudo chown <MAPR_CONTAINER_UID>:<MAPR_CONTAINER_GID> <path on Docker host to MapR ticket>
Access Control Errors when Creating Hive Tables
- Problem
When creating Hive tables, you encounter an
AccessControlException.- Possible Cause
This is likely a permission issue. Check the permissions on the Hive Warehouse Directory whose default location is
/user/hive/warehouse. The permissions on the directory must be 777.- Resolution
- Update the permissions if not already set to 777:
hadoop fs -chown 777 /user/hive/warehouse