Configuring the Livy Interpreter
The Livy interpreter provides support for Spark Python, SparkR, Basic Spark, and Spark SQL jobs. To use the Livy interpreter for these variations of Spark, you must take certain actions, including configuring Zeppelin and installing software on your MapR Data Platform cluster.
You must also issue your docker run command with the parameters the Livy
interpreter requires. See the following material for details about these
parameters:
Spark Python
The Apache Livy interpreter supports both Python 2 and Python 3, but you can run only one or the other in your container. You must install the Python packages on your MapR cluster to use them through Livy. You do not need to install them in your container.
To use Python, specify the following in your notebook:
%zeppelin.livy.pysparkBy default, this invokes Python 2. To switch Python versions, see Python Version.
To install custom Python packages, see Installing Custom Packages for PySpark.
SparkR
You must install R on your MapR cluster to use Apache SparkR through Livy.
To install custom packages for SparkR, run the R interpreter and execute R commands to install the target package. You must install the packages on each node where SparkR will execute. This are the nodes that contain a YARN NodeManager. By default, the Livy interpreter submits Spark jobs in YARN cluster mode.
The following example installs the data.table and
googleVis packages using the R interpreter:
sudo R
> install.packages("data.table")
> install.packages("googleVis")%zeppelin.livy.sparkr
print(packageVersion("data.table"))
print(packageVersion("googleVis"))[1] '1.10.4.3'
[1] '0.6.2'Spark Jobs
By default, the Livy interpreter is configured to submit Apache Spark jobs in YARN cluster mode.
To run Spark jobs in parallel, you must modify the Livy interpreter to instantiate Per Note:
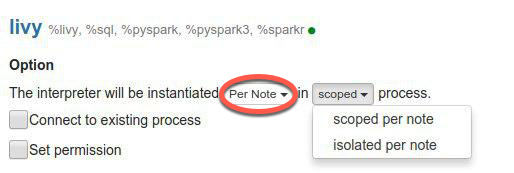
You can set scoped to either of the two options.
Hive Tables
To use Apache Spark SQL with Apache Hive, follow the steps described at Integrate Spark-SQL (Spark 2.0.1 and later) with Hive. As described on that page, to access Hive tables through Spark, you must make
the hive-site.xml configuration file from your Hive cluster
available to Spark running in your Zeppelin container.
One way to make the file available is through a volume mount when you start Docker:
- Copy the file
/opt/mapr/hive/hive-<version>/conf/hive-site.xmlfrom your Hive cluster to the local host on which you are running the Docker container. - Add a volume mount argument to your
docker runcommand.In the following example, the local
hive-site.xmlfile is in/tmp:docker run -it -p 9995:9995 -e MAPR_CLUSTER=<cluster-name> … \ -v /tmp/hive-site.xml:/opt/mapr/spark/spark-2.3.1/conf/hive-site.xml:ro \ maprtech/data-science-refinery:v1.4.1_6.1.0_6.3.0_centos7
Another way to make the file available is to copy it into your running container:
- Copy the file
/opt/mapr/hive/hive-<version>/conf/hive-site.xmlfrom your Hive cluster to the local host on which you are running the Docker container. - Determine your
container-idusing the output from the following command:docker ps - Copy
hive-site.xmlfrom your local host into your Docker container:docker cp /tmp/hive-site.xml <container-id>:/opt/mapr/spark/spark-2.3.1/conf - Log in to your container as the user running the container using the
container-id:docker exec -it --user <MAPR_CONTAINER_USER> <container-id> bash -l - Restart the Livy service running in your container:
/opt/mapr/zeppelin-livy/zeppelin-livy-<version>/bin/zeppelin-livy-server stop /opt/mapr/zeppelin-livy/zeppelin-livy-<version>/bin/zeppelin-livy-server start