Configuring the JDBC Interpreter for Apache Drill and Apache Hive
Apache Zeppelin on the MapR Data Platform includes custom JDBC interpreters for Apache Drill and Apache Hive. Fields in each interpreter are prepopulated, but you need to customize them for your environment.
In particular, you must modify the JDBC URL, as described in the following sections.
Drill JDBC
You can set the default Apache
Drill JDBC URL by specifying environment variables in your docker run
command. See Default Drill JDBC Connection URL for
details. To make additional changes to the URL, modify the default.url
property:
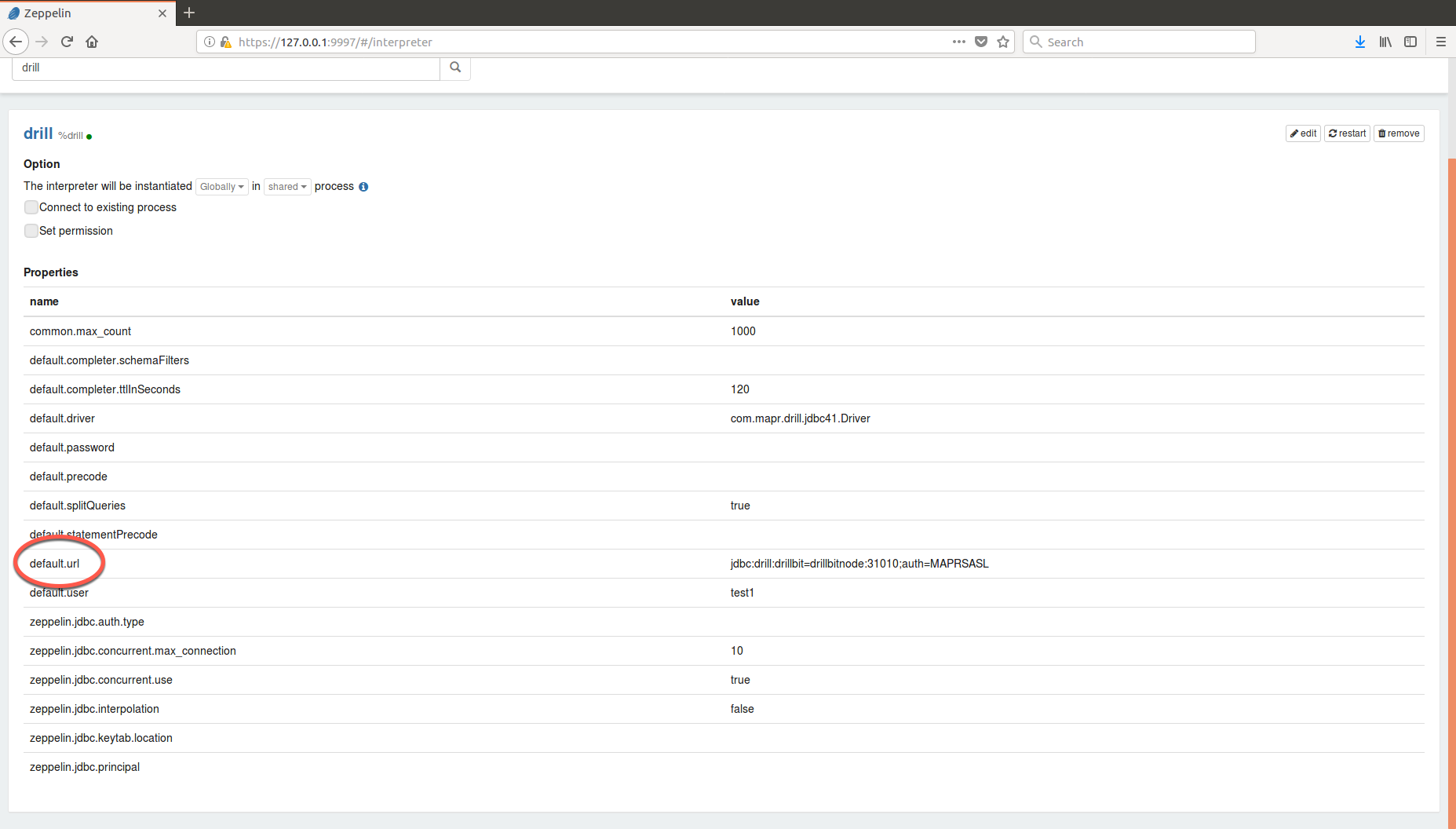
jdbc:drill:drillbit=drillbitnode:31010;auth=maprsasljdbc:drill:drillbit=node1:31010For non-secure clusters,
default.user is prepopulated with the user running the container
(MAPR_CONTAINER_USER). You can modify this property and
default.password, as needed. Zeppelin submits your Drill queries using this user
name and password (if specified).
For secure clusters, Zeppelin always submits Drill
queries using the user name and password from your MapR ticket. You do not need to modify the default.user and
default.password properties.
Hive JDBC
You must specify the Apache Hive
JDBC URL in the default.url property:
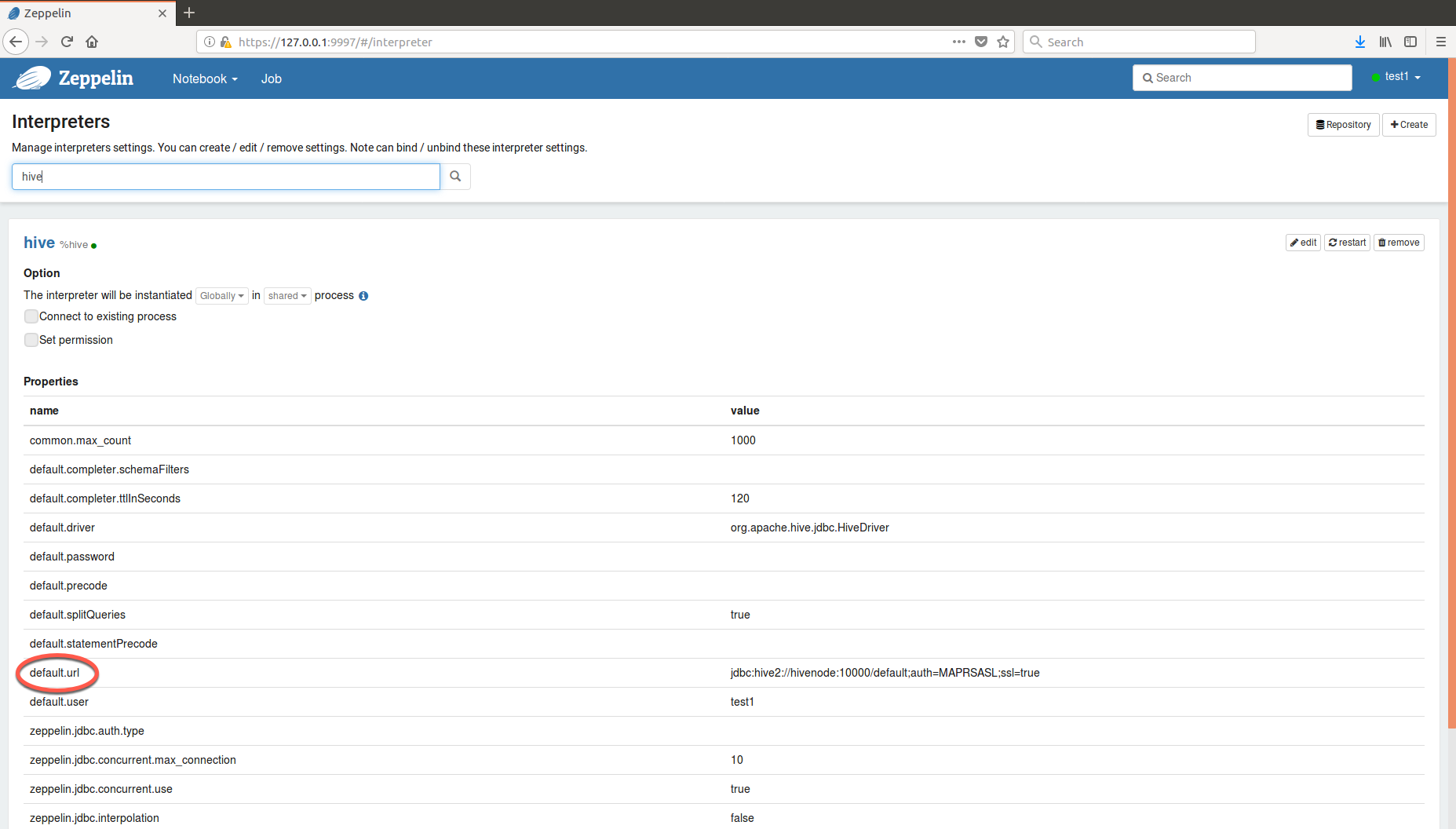
jdbc:hive2://hivenode:10000/default;auth=maprsasl;ssl=truessl=true after MapR-SASL is
enabled.jdbc:hive2://node2:10000/default