Data Offload and Purge
Describes the process of offloading data to warm and cold tiers, and purging data from storage pools.
- The schedule set at the volume level for offload.
- The request triggered by the client (through the Control System, the CLI, or REST API).
On volumes configured for warm tiering, the MAST Gateway service detects the files that meet the criteria in the configured rules, collects data to offload from the read-write containers of the front-end volume on the MapR file system, and:
- Creates objects based on the erasure coding scheme.
For example, for an erasure coding scheme of 4 + 2 and stripe depth of 4 MB, which is the default, the object size is 4 x 4 MB = 16 MB and the stripe length is 6 x 4 MB = 24 MB. When offloading an individual file, the file must contain data exceeding 90% of the object payload to qualify for offload. When offloading a volume, an object can contain multiple small files, and the per-file payload requirement does not apply. Still, any objects that fall below the threshold are not offloaded.
NOTE Data is broken into many fragments (or m pieces) and encoded with some extra redundant fragments (or n pieces) to guard against disk failures. - Prepares a corresponding metadata on the MapR cluster for the data.
The MAST Gateway stores the metadata in MapR Database tables in a separate volume associated with the tier.
- Offloads the objects to the tier. NOTE If an object contains less than 90% of the object payload, the object is not offloaded and the metadata table is not updated; the volume might have local data. However, the MAST Gateway will report successful job completion.Data is offloaded to the tier in the same state, compressed or uncompressed, as was stored in the front-end volume. If data encryption is enabled on the front-end volume (using the
dareparameter), data is encrypted during and after offload to the erasure-coded volume.
The following illustration shows the CLDB notifying the MAST Gateway service to start the offload (#1) and the MAST Gateway fetching data from the front-end volume (#2), offloading the data to the associated erasure-coded volume (#3), and then writing metadata to the tier volume associated with the front-end volume (#4).
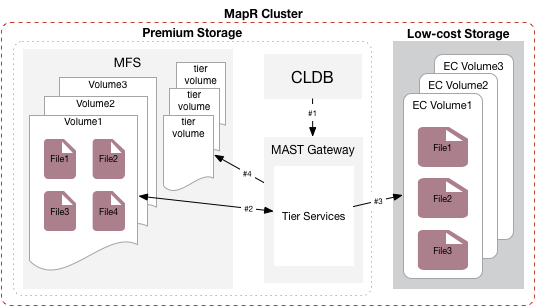
As stated above, when offloading an individual file, it might not qualify for offload because objects that contain less than 90% of the object payload do not qualify for an offload. For example, assume that you have a 15 MB file in a volume enabled for warm-tier erasure coding scheme 4 + 2. The object size for the volume is 16 MB (4 x 4 MB). Thus, an individual file of 15 MB is less than 90% of the object payload. In this case, a 15 MB file does not qualify for file offload by itself.
Similarly, portions of a large file might not qualify for offload. For example, assume that you have a file in the volume enabled for warm-tier erasure coding scheme 4 + 2 is 20 MB. The object size for the volume is 16 MB (4 x 4 MB), and the individual file of 20 MB exceeds the upper limit of the object payload. Portions of data in the file are offloaded, and up to 4 MB of file data might remain on the hot tier.
When offloading a volume, smaller files can be combined into an object for offload. Still, some portions of those files might not be placed in objects that exceed the 90% payload threshold. Those portions of the file will not be offloaded.
On volumes configured for cold tiering, the MAST Gateway service detects the files that meet the criteria in the configured rules, collects data to offload from the read-write containers and snapshots for the volume on the MapR file system, and:
- Packs 64 k data chunks into 8 MB-sized objects.
- Creates the bucket on the tier (or remote target) if the specified bucket is already not present on the tier.
- Prepares corresponding metadata on the MapR cluster for the data and creates the
objects in the tier.
The MAST Gateway stores the metadata in MapR Database tables in a separate volume associated with the tier.
- Offloads the data to the tier using libcurl.NOTE Data is offloaded to the tier in the same state, compressed or uncompressed, it was stored on the MapR File System. If data encryption is enabled at the volume level (using theFor the offloaded data, the unique object IDs are generated using a combination of cluster ID, volume ID, and a unique sequence of numbers. For example, the names of the objects in S3 can look similar to the following:
tierencryptionparameter), data is encrypted during and after offload. Seevolume createorvolume modifyfor more information about the parameter.0.b258a07.86e.1 0.b258a07.86a.1 0.b258a07.86c.1
The following illustration shows the CLDB notifying the MAST Gateway service to start the offload (#1) and the MAST Gateway fetching data from the volume (#2), offloading the data to the third-party storage alternative (#3), and then writing metadata to the tier volume associated with the volume (#4).
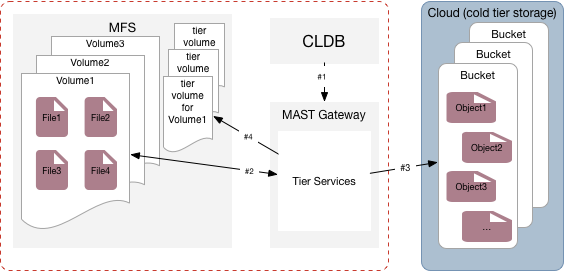
The MAST Gateway service notifies the CLDB when the offload operation completes successfully. Entire volumes can be moved from "hot" to "warm" tier or "hot" to "cold" tier and vice-versa on demand by using CLIs. For each offloaded volume, the MapR File System stores only the metadata for the offloaded data in a volume on the hot tier.
See also: Offloading a Volume to a Tier and Offloading a File to a Tier Using the CLI and REST API
Purging Data on MapR File System
While offloading, metadata is written to the MapR Database table in a separate volume associated with the tier, and the data blocks are removed from the storage pool in the hot-tier. An offload is considered successful only when data on all active replicas has been purged (or removed from the storage pool to release the disk space on the MapR file system) in the hot-tier. When you offload data at the file level, all data, including recalled data, is immediately purged from the hot-tier. For more information, see Data Compaction.