Log Compaction
Log compaction purges previous, older messages that were published to a topic-partition and retains the latest version of the record.
Log compaction reduces the size of a topic-partition by deleting older messages and retaining
the last known value for each message key in a topic-partition. The
mincompactionlag parameter provides a lower bound on how long each message
remains prior to compaction and the deleteretention parameter provides a
lower bound on how long a tombstone (a message with a null value) is retained. See the maprcli
stream create and stream edit commands and Enabling Log Compaction for more information about these retention parameters.
- Application recovery time - Since log compaction retains the last known value, it is a full snapshot of the latest records. It is useful for restoring state after a crash or system failure.
- Storage space - This becomes noticeable when there is a high volume of messages.
Compaction Process
Log compaction is implemented by running a compaction process in the background that identifies duplicates, determines whether older messages exist, and purges older messages from the topic-partition.
The following diagram shows an initial message (published to a topic-partition) that is identified by the key-value pair, K1V1. When a subsequent message (K1V2) is published to the topic-partition, based on it's key-value pair, it is identified as a duplicate. The compactor then deletes the older message (K1V1) from the topic-partition.

Log compaction never re-orders messages, just deletes them. Any consumer reading from the start of the log sees at least the final state of all records in the order they were written. In addition, the offset for a message never changes.
Compaction and Gateways
The log compaction process uses a gateway that has an internal index and a compactor. The internal index tracks message key-value pairs. this allows duplicate messages in the topic-partition to be identified. Based on the identification of duplicate messages, the compactor runs the compaction process which purges the older message from the topic-partition. This process results in stream data being compacted.
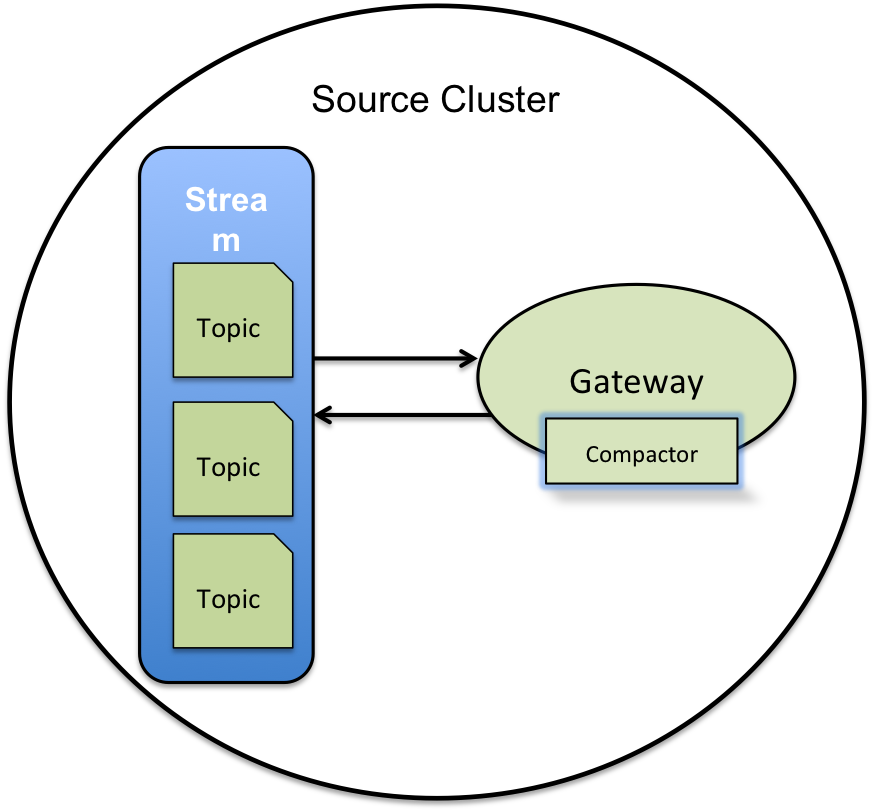
The number of gateways impacts the compaction process, in that, increasing the number of gateways on the cluster improves the load distribution of the log compaction activity.
Stream Replication
When a stream on a source cluster has both log compaction and replication enabled, the replica cluster does not automatically have log compaction enabled. You must explicitly enable log compaction on the replica cluster.
If a replica cluster has been upgraded and the stream data for a source cluster is compacted (that is, one or more messages have been deleted), then the source cluster replicates the compacted data to the replica cluster.
- Fails the replication.
- Automatically retries replication with an exponential backoff.
- Resumes replication when the replica cluster has been upgraded.
maprcli stream replica status command. This error requests that you
upgrade the replica cluster.