MapR Edge
This section contains information about MapR Edge, which is a small footprint edition of the MapR Data Platform. MapR Edge is designed to capture, process, and analyze IoT data close to the source.
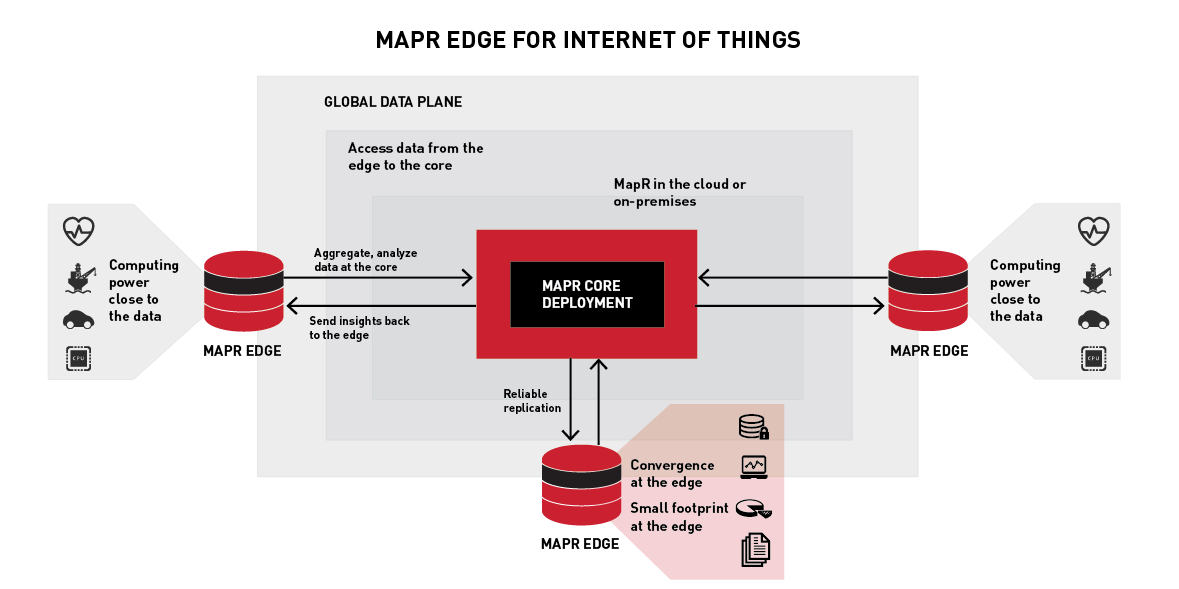
MapR Edge is a small footprint edition of the MapR Data Platform and you can use it to capture, process, and analyze IoT data close to the source.
MapR Edge is a fully-functional MapR cluster that can be run on small form-factor commodity hardware, such as Intel NUCs. MapR Edge clusters are supported in three- to five-node configurations. Each cluster supports the full capabilities of the MapR, including the capacity for files, tables, and streams, along with related data management and protection capabilities such as security, snapshots, mirroring, replication, and compression.
Installation, Configuration, and Management
Install, configure, and manage MapR Edge clusters and nodes the same way you handle traditional MapR clusters and nodes. Each cluster is managed and monitored independently.
If you are installing an MapR Edge cluster, you must ensure to configure the nodes according to the guidelines in the table below (MapR Edge Supported Cluster Configuration). Pay special attention to node hardware minimums and maximums, the number of supported storage pools, and caveats around upgrades and failure tolerances for different cluster sizes.
All MapR Edge clusters must be deployed in conjunction with a core MapR Edge cluster. You must use one or more of the MapR data-replication features to synchronize data from Edge-to-Core, such as MapR mirroring, MapR Database table replication, or MapR Event Store For Apache Kafka replication.
MapR Edge Supported Cluster Configuration
Before you architect your system to use MapR Edge, consider the following supported-configuration specifications:
| Specification | Value | ||
| Number of Nodes1 Per Cluster | Three2 | Four2 | Five |
| Max No of Data Drives Per Node | Up to 4 | ||
| Storage Capacity (Usable)3 | Min : 64GB Max : 10TB | ||
| Replication Factor | Up to 3X | ||
| No. of Storage Pools (per Node) | 1 | ||
| Cluster Failure Tolerance 4 | 1 node | 2 nodes | |
| Node Config Types | Homogeneous5 | ||
| Boot Disk Per Node | 1 (Min 20GB) | ||
| Processing Services | Spark, Drill | ||
| Included Software | MapR File System, MapR Database, MapR Event Store For Apache Kafka | ||
| Node Hardware Specs |
CPU-Type : x86(64Bit), Cores: 2 - 4, RAM: 16 - 32 GB, Disk-Type : SATA,SAS,SSD, vDisk Speed: 1Gb minimum, 10Gb |
||
| Online Software Upgrade and Patching | Offline Upgrade or Rolling Upgrade | ||
| Supported Core Software Version | Release 5.2 and later | ||
| Supported Deployments | Bare Metal or Virtual Instances | ||
1 Node is defined as “data node” or a node running a FileServer process. The node is responsible for storing data on behalf of the entire cluster. Nodes deployed with control-only services like CLDB and ZooKeeper do not count towards minimum node count as they do not contribute to overall availability of data
2 Clusters with less than 5 nodes may exhibit variable performance, especially during times of failure recovery when node resources are consumed with re-replication of data.
3 Usable storage defined by total disk size divided by replication factor.
4 This defines how many failures a cluster can sustain and still keep the cluster accessible to its clients/apps. Definition of failure includes anything that makes a node become unavailable, including hardware failure, software failure, disk failure, network failure, or power failure. HPE cannot assure data integrity for any additional failures beyond this count.
5 All nodes must be exactly same in terms of capacity, including number of drives, amount of memory, type of cpu, and so forth.
Additional Design Considerations for Edge Clusters
- Continuously moving critical data from the edge cluster to a core cluster using MapR replication features like mirroring, MapR Database table replication, and streams replication. This strategy minimizes RPO/RTO in case of multi-failure scenarios.
- Limiting reliance on any single point of failure infrastructure, such as chassis, power source, disk, or network device. Power and network redundancy are strongly recommended. This decreases the likelihood of a multiple failure scenario.