Secondary Index Concepts
Describes secondary index concepts, including use cases, types of indexes, types of queries that benefit from indexes, and how indexes are implemented.
Indexes created on regularly queried JSON table fields provide MapR Database quick access to data. Indexes primarily benefit queries with filters in the WHERE clause, queries with an ORDER BY clause for sorting, and queries where all fields projected in the query are included in the index. They provide the most benefit when an index contains all fields referenced in a query. For filters, indexes reduce the amount of data read. MapR Database implements indexes using JSON tables. Like JSON tables, an index stores data in sort order. Reading data through the index eliminates the need to sort the data if the index and query sort orders match.
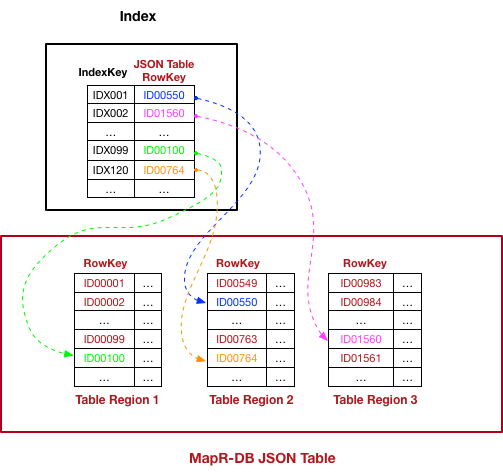
Each JSON table in MapR Database has a unique field that serves as the rowkey. A secondary index contains indexed and included fields. The indexed fields, also referred to as index keys, define the sort order of the index. The index stores the values of the index keys along with the rowkey corresponding to each key value. The rowkey links the index to the JSON table. MapR Database can perform a range scan on the index and then use the corresponding rowkeys to quickly locate data in the JSON table. Additional fields can be included in the index so that queries that only need these included (or covered) fields can get all the data they need from the index and therefore will not require access to the base table.
The following diagram illustrates the mapping. Each index entry consists of the index key value followed by the rowkey of the corresponding JSON document. The color coding highlights the matching index and JSON table entries.