Selection and Execution of Secondary Indexes
This section provides an overview of secondary index selection and execution in MapR Database JSON. It describes the variations in functionality, depending on the components you are using.
The following diagram summarizes the code paths and the components involved when using secondary indexes in MapR Database JSON. See OJAI Distributed Query Service for more information about the components and code paths.
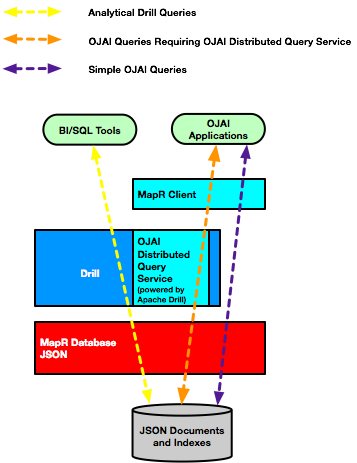
Index Selection
All three code paths use a cost-based approach to select an optimal query plan. Cost based optimization chooses between alternatives where it may not be obvious which is the better index to use. Assume that you have the following two indexing options:
- Index 1 can be used to filter condition A in a query but cannot satisfy the sort criteria.
- Index 2 can be used to filter condition B in a query and also satisfy the sort criteria.
If filter condition A is more selective than filter condition B, although using index 1 requires reading less data, it requires a sort of the data. In contrast, using index 2 requires reading more data but does not incur the cost of sorting the data. A cost based optimizer estimates the cost of both options and chooses the one with the lower cost. It also estimates the cost of a full table scan. It may choose the full table scan if the index-based plans do not use selective filters.
The Simple OJAI Query code path can use indexes even when a query does not have filter or ORDER BY conditions that match the fields of an index. See Using Indexes to Optimize Projections in Queries for details.
The Drill query optimizer and the optimizer used by the OJAI Distributed Query Service can select multiple indexes to process a query. The OJAI Distributed Query Service scans the indexes and takes the intersection of the matching documents from each index. The MapR client invokes scans of only a single index.
The rest of this section generally discusses the optimizer flow. Except where noted, the discussion applies to the optimizer used in all three code paths.
MapR Database gives the optimizer a list of indexes associated with the JSON table referenced in the query. The optimizer enumerates through the possible index choices using the following steps:
- Identifies the set of indexes whose keys match filter conditions and possibly also the ORDER BY specification.
- Estimates the cost of using each index.
- Considers combinations of indexes and estimates the cost of these combinations. (Applies to the Drill and OJAI Distributed Query Service optimizers only.)
Using the cost estimates, the optimizer selects the index (or indexes) with the lowest cost, or if appropriate, a full table scan. The cost is a function of the index properties, table size, and selectivity of the filter conditions applied. Each of these factors contribute to the estimated cost in the following ways:
- Index Properties
- MapR Database provides the Drill optimizer with index properties. Index properties include the fields that comprise the index, whether the field is an indexed or included field, and the sort direction of each indexed field.
- Table Size
-
MapR Database maintains information about table regions, including table size. The optimizer uses table size when calculating the cost of the query plan.
If JSON tables are small and fit into a single region, the overhead of using indexes on the table may not provide enough performance benefits to justify an index-based plan. In such a scenario, the optimizer could calculate a full table scan as cheaper to perform than an index scan, rendering any index on the table unnecessary. Even if you apply selective filters on small tables, the overhead of using indexes may not provide performance benefits.
- Filter Selectivity
-
Filter Selectivity is the estimated number of rows based on the selectivity of each conditional expression in the WHERE clause. Filter selectivity is calculated as:
(output row count)/(total table row count)For example, if you have 100 documents and 25 documents qualify the filter condition, the selectivity is .25.
Filter selectivity ranges between 0 and 1. The closer to 0, the more selective the filter. The more selective a filter, the lower the cost. High filter selectivity results in better query performance. If filter conditions are not selective enough for the optimizer to choose the index, remove the index to free up storage.
For example, defining an index on a field like
gender, which has only two possible values, does not result in selective filtering. Consider adding other fields to define a composite index to make filtering with that index more selective. In general, define indexes on high cardinality fields unless your queries also sort on those fields.For covering queries, Drill selects an index plan if the number of rows selected is less than or equal to .75 of the total number of rows in the JSON table. If the number of rows selected is greater than .75 of the total number of rows in the JSON table, Drill performs a full table scan.
For non-covering queries, the threshold is .025.
Index Execution
After either the MapR client or Drill select an optimal query plan, MapR Database has the index (or list of indexes, in the case of a plan generated by Drill) from which to read. It reads the index to retrieve the corresponding documents from the JSON table. The following diagram and table illustrate the flow for a read from a composite index created on fields a and b.
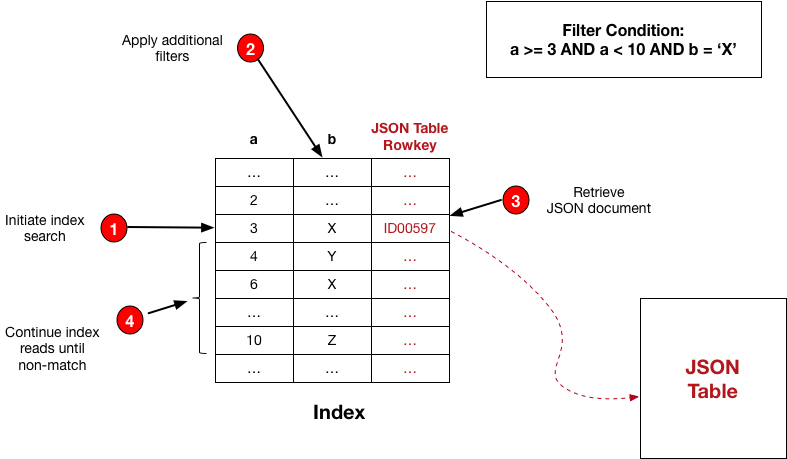
| Step # | Description | Details |
|---|---|---|
| 1 | Initiates index search | MapR Database searches the index, starting
at the condition a >= 3. |
| 2 | Applies additional filters |
MapR Database applies the filter condition on
field For example, when |
| 3 | Retrieves JSON document | Using the rowkey in the entry, MapR Database reads the corresponding JSON document. |
| 4 | Continues index reads until non-match |
MapR Database reads the subsequent index keys
provided they match the filter condition For example, the reads stop when MapR Database
reads the value 10 from field |