Administering MapR Gateways
A MapR gateway mediates one-way communication between a source MapR cluster and a destination cluster. You can replicate MapR Database tables (binary and JSON) and MapR Event Store For Apache Kafka streams. MapR gateways also apply updates from JSON tables to their secondary indexes and propagate Change Data Capture (CDC) logs.
The initial task for setting up your gateways is to decide where you want to put them:
- If you are going to replicate MapR Database tables, see Gateways for Replicating MapR Database Tables.
- If you are going to replicate streams, see Gateways and Stream Replication.
- If your MapR Database JSON tables have secondary indexes, see Preparing Clusters for Querying using Secondary Indexes on JSON Tables.
- If you are using CDC, see Getting Started with CDC.
However, the resource that gateways use the most is network bytes. For example, if the peak network throughput for puts is about 40 MB per second per node, in a 10-node source cluster the peak network throughput will be about 400 MB per second. So, the aggregate network throughput required on the nodes running gateways will be 400 MB per second for both incoming and outgoing traffic. The aggregate network throughput for a 50 node cluster would be 2GB per second.
For another example, in the following diagram there are two source clusters of three nodes each and the clusters are replicating to one destination cluster. The peak traffic on the gateways will be 40MB per second per cluster node, which means that these gateways together will experience a peak network load of 240MB per second.
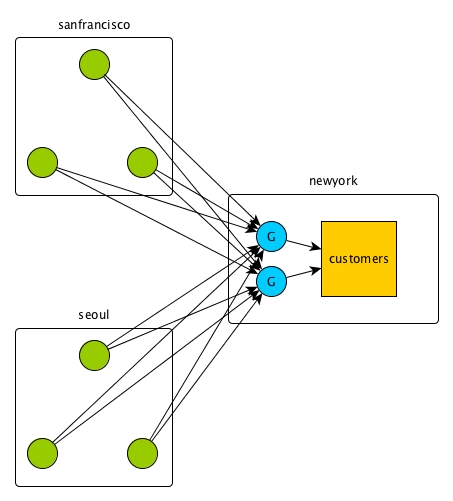
Although the load is balanced across the two gateways, so that each gateway experiences a peak network load of 120MB per second, each gateway should be able to tolerate the full aggregate network load in case the other gateway fails unexpectedly.