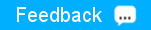
Column Families in JSON Tables
JSON tables store data in column families, which are collections of fields that are stored together on disk.
Each table has a default column family, which is default storage for all fields in the documents of a table. You can create additional column families to store data for a collection of fields in a separate location on disk. Queries and other operations only on data that is stored in a column family are more efficient and better performing than queries on the same data when that data is stored with other data in a table. You can also cache values from a column family in memory.
For example, suppose that you have three OJAI documents in a table, and all three have the
field a.
a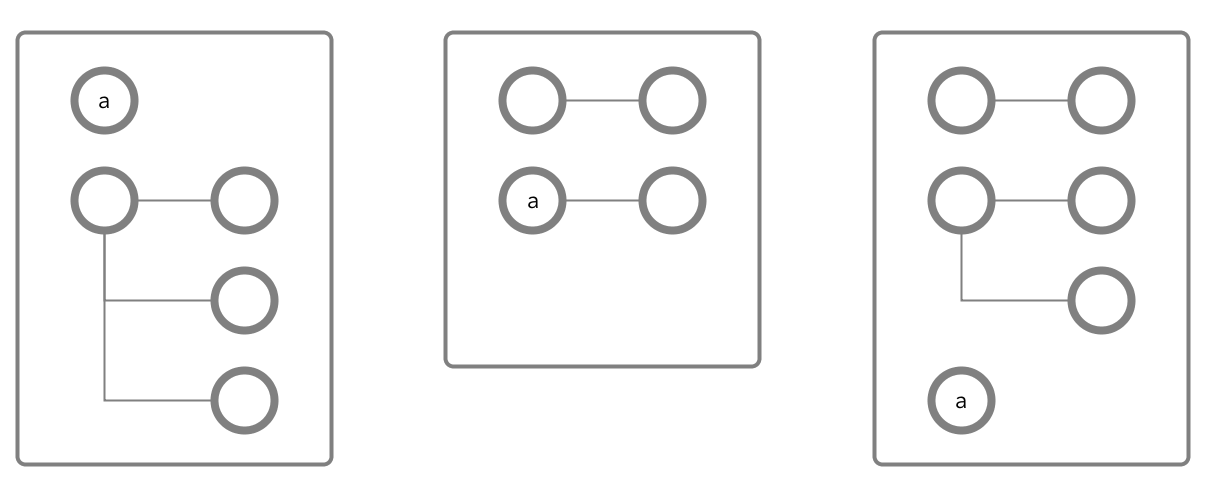
At this point, you have not yet created any non-default column families. So, all of the data in the table resides in the default column family. Each JSON table is created with a default column family.
To optimize data access for your applications, you plan to place some data that will be
heavily queried in a new column family at path a.b, where
b is a field that does not yet exist. Fields do not yet have to exist
before you create column families on them.
You create a column family at the path a.b and with the name
CF1.
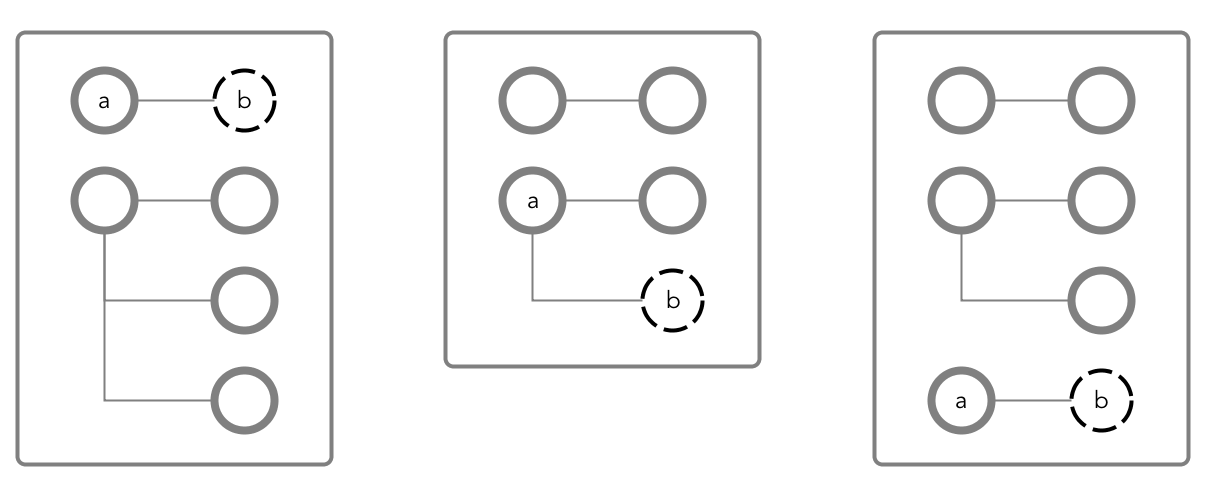
When field b is created, that field will belong to the column family
CF1. All values of b, as well as the values of all
fields that might be created after b, will be stored together on disk.
Applications can read data directly from this column family and avoid reading the rest of
the document at the same time, making queries more efficient and therefore faster.
CF1 in black
You can create up to 64 column families in a JSON table. The column
families can be at any location in your documents. For example, these two documents both use
the same non-default column families at the paths a.b,
a.b.c, and d.
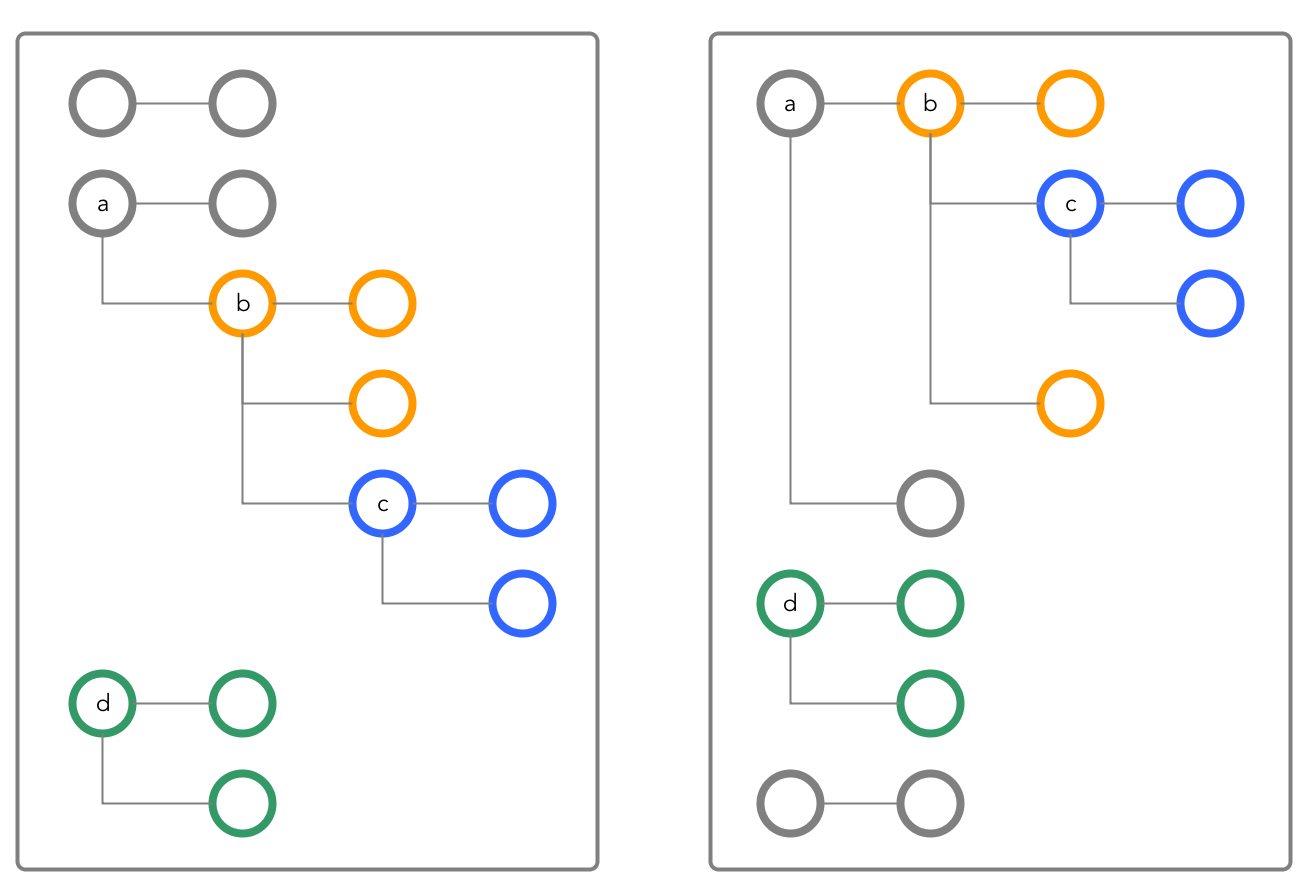
If the path at which you want to create a column family already exists, it is recommended that the path and any fields below it contain no data. After the conversion of the path to a column family, it is possible that data existing in the path before the conversion could become inaccessible.
Applications do not need to be aware of the existence of column families. They perform CRUD
operations by using the paths of fields in a document. For example, to update any of the
fields below a.c, an application does not need to be aware that the field
is in the column family at the path a.c. The application simply moves
through the document along the path to the field.